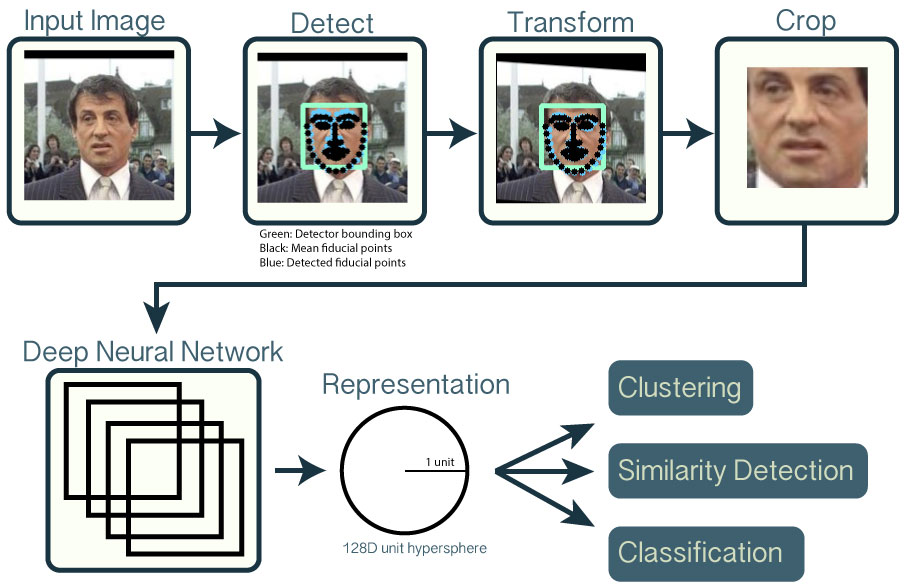
openface로 얼굴 판별
휴대폰으로 사진을 열심히 모았지만, 너무 많아 태그를 입력할 엄두가 나지 않았다. 입력할 때 파일의 정보를 추출하여 데이터 베이스에 정리했다. 언젠가 […]
휴대폰으로 사진을 열심히 모았지만, 너무 많아 태그를 입력할 엄두가 나지 않았다. 입력할 때 파일의 정보를 추출하여 데이터 베이스에 정리했다. 언젠가 […]
gimp를 사용하면, 마우스를 많이 클릭해야 한다. 대부분 노가다인데, python-fu를 사용하면 반복 작업을 대폭 줄일 수 있다. 필터 메뉴에서 python 콘솔을
아나콘다에 tensorflow를 설치하여 사용했다. 그러나 1.6버전 이후로 tensorflow를 import하면 illegal instruction을 내고 죽었다. 혹시나 해결되었는지 1.10으로 업데이트하여 확인했다. 그러나 역시
한 5년 사용하던 마우스 왼쪽 버튼이 잘 눌리지 않았다. 고쳐보려고 찾아봤는데, 결과적으로 죽어가는 마우스를 부셔 버렸다. 마우스 커버 뜯기. 작은
매번 인터넷에서 찾다쓰다, 귀찮아 나중에 한번에 쓰기 위해 기록한다. 아래 사이트를 참조했다. 지운 후, rollback https://stackoverflow.com/questions/11011384/how-to-test-an-sql-update-statement-before-running-it inner join http://rapapa.net/?p=311 중복