원격 조종기 만들기
집에서 놀고 있는 안드로이드 폰으로, LEGO EV3을 조종하는 리모콘을 만들어 보려고 한다. 갤럭시 노트1 조종기 개념 화면에 포켓 몬스터 볼을 […]
집에서 놀고 있는 안드로이드 폰으로, LEGO EV3을 조종하는 리모콘을 만들어 보려고 한다. 갤럭시 노트1 조종기 개념 화면에 포켓 몬스터 볼을 […]
텐서플로우 GPU 버전을 설치하면 최고인데, CPU 버전만 사용해야 한다. CPU 버전을 쓰면 아래와 같이 메세지가 나온다. (tensorflow) now0930@:cifar10$ python cifar10_testv1.py

디아블로3 : 영혼을 거두는 자 구매 인터넷을 뒤지다보니 디아블로3가 망한 게임에서 탈출했음을 보았다. 2012년 제품 출시 당시, 최단 기간 가장
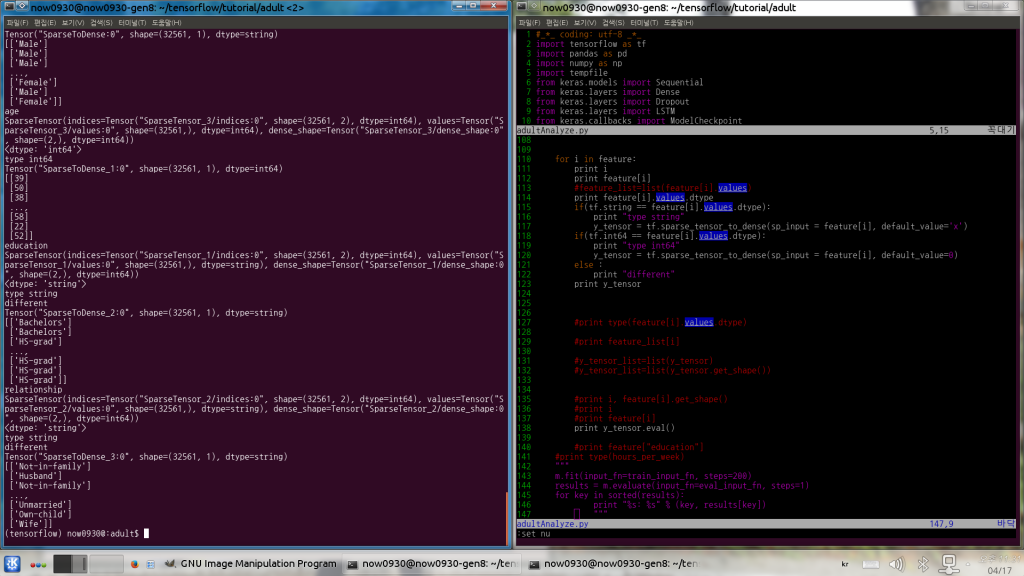
sparse_tensor_to_dense 전에 이어서… 각 행의 feature를 sparse tensor로 받아 들인다. tutorial에는 값을 확인하는 부분이 없다. 내가 입력한 값이 정확한지 이를

데이터 얻기 데이터 셋을 무료로 제공하는 사이트에서 미국 성인 나이, 학력, 가족관계, 년 소득을 받을 수 있다. 입력된 데이터로 이