지금 엽서를 거의 사용하지 않는다. 어렸을 때 설악산 사진엽서 부모님께 보낸 일을 기억한다. 지금은 없지만 크리스마스 실을 샀던 일을 기억한다. 그 실을 엽서나 편지에 붙여 친구에게 보냈어야 했는데, 나는 책상에 보관하다 버렸다. 한국인이 엽서를 사용하지 않음은 좀 특이하다. 미국 홀마크는 카드를 주로 만드는데, 그 매출이 꽤 된다고 알고있다. 나는 아직도 엽서를 보낸 기억이 없다.
이 책으로 엽서가 가능 기능을 생각한다. 조선 근대 사진(엽서)은 제국주의 충실한 도구로 그 생각을 대중에게 전파했다. 특히 일본은 사진이 주는 권력을 잘 이용했다. 여기 실린 엽서도 조선 후진성, 서양 시각에서 바라본 착취대상으로 조선을 벗어나지 않는다. 우리가 근대를 자주적으로 보냈다면 엽서가 반짝였겠지만, 여기 실린 엽서는 낡고, 초라하다.
비록 낡고 후졌지만 과거 조선이 어땠는지를 알 수 있다. 그러나 그 주제가 건축물, 인물 등으로 제한됨은 어쩔 수 없다. 일제가 이런 주제로 조선 상황을 외국에 알렸다.
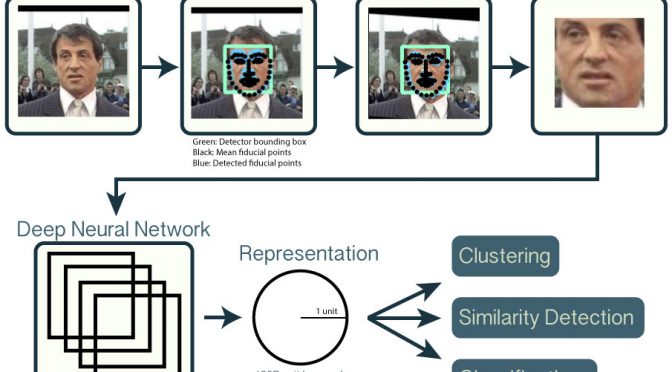
휴대폰으로 사진을 열심히 모았지만, 너무 많아 태그를 입력할 엄두가 나지 않았다. 입력할 때 파일의 정보를 추출하여 데이터 베이스에 정리했다. 언젠가 얼굴을 인식하는 소프트웨어를 응용하여 판별하려고 했는데, 2016년 정도에 개발된 openface를 찾았고 이를 사용하기로 했다. 인터넷의 누군가 좋은 튜토리얼을 (영문)만들었고 이를 많이 참조했다. 또한 openface가 수정없이 그대로 사용할 정도의 완성도를 보여준다. docker 이미지로 제공되는데 바로 사용할 수 있다.
목표한 4명의 얼굴을 학습시켰고, 이 모델을 기반으로 모든 파일을 분류 했다. 모델을 만들기는 금방인데, 사진에서 얼굴찾기, 그 얼굴이 누구인지는 확인하기 위해서는 많은 시간(내가 가진 PC로 3일..)을 썼다. 얼굴 인식 후 이를 파일로 기록하였고 아래와 같다.
=== /root/picture/사진/20150211_202325.jpg ===
=== /root/picture/사진/MyPhoto_0149.jpg ===
Predict Daewon @ x=2075 with 0.66 confidence.
=== /root/picture/사진/20140412_162452.jpg ===
List of faces in image from left to right
Predict Minsu @ x=1377 with 0.63 confidence.
Predict Daewon @ x=1549 with 0.86 confidence.
Predict Minsu @ x=1780 with 0.60 confidence.
Predict Daewon @ x=1893 with 1.00 confidence.
=== /root/picture/사진/20130219_152444.jpg ===
Predict Daewon @ x=63 with 0.52 confidence.
=== /root/picture/사진/20121208_110821.jpg ===
=== /root/picture/사진/사진110702_003.jpg ===
=== /root/picture/사진/사진120207_010.jpg ===
Predict Minsu @ x=732 with 0.59 confidence.
=== /root/picture/사진/20140405_160811.jpg ===
Predict Miae @ x=1288 with 0.99 confidence.
=== /root/picture/사진/20140406_085437_ShearesAve.jpg ===
Predict Daewon @ x=775 with 0.98 confidence.
=== /root/picture/사진/20131013_134752_과천동.jpg ===
가끔 한 파일에 여러 이름을 기록하는데, 아마 학습하지 않은 인물이 사진에 있기 때문이다. 신뢰도 0.8 미만이면 믿을 수 없다고 판단하여 지웠다. 공백을 지우고, 여러 행을 한 행으로 만들기 위해 다음 python 스크립을 사용 했다. sed를 사용하려 했으나, python이 낫다. docker로 디렉토리를 root 아래에 바로 마운트하여 경로에 root가 포함되었다. vim으로 해당 경로로 모두 변경했다. 데이터베이스에 굳이 신뢰도와 얼굴 위치를 넣지 않아도 되어 모두 지웠다.
#_*_ coding: utf-8 _*_
import re
import sys
from signal import signal, SIGPIPE, SIG_DFL
signal(SIGPIPE,SIG_DFL)
result_file = open('./resultv3.txt','r')
flag_found_path=False;
flag_found_prediction=False;
num_lines = sum(1 for line in open('./resultv3.txt'))
for x in range(num_lines):
context=result_file.readline()
#path를 찾는부분.
path = re.compile("=== .* ===")
searched_path = path.search(context)
#predict를 찾는 부분
prediction = re.compile("Predict.*")
searched_prediction = prediction.search(context)
#===로 시작하는 부분.
if searched_path != None:
flag_found_path=True
#간단한 버전.
path_str = searched_path.group()
print('\n'+path_str,end=',')
if searched_prediction != None:
predict_str = searched_prediction.group()
print(predict_str,end=',')