임베디드 CPU와 임베디드 GPU에 대해 궁금하신가요? 임베디드 CPU는 중앙 처리 장치(Central Processing Unit)의 약자로, 컴퓨터나 임베디드 시스템의 핵심 부품입니다. 임베디드 CPU는 다양한 명령어를 수행하고, 데이터를 처리하고, 입출력 장치와 통신하는 역할을 합니다. 임베디드 GPU는 그래픽 처리 장치(Graphics Processing Unit)의 약자로, 컴퓨터나 임베디드 시스템의 그래픽 성능을 향상시키는 부품입니다. 임베디드 GPU는 이미지, 비디오, 애니메이션 등의 그래픽 관련 작업을 전문적으로 처리하는 역할을 합니다.
임베디드 CPU와 임베디드 GPU는 일반적인 CPU와 GPU와 비슷한 기능을 하지만, 임베디드 시스템에 특화된 특징을 가집니다. 임베디드 시스템은 제한된 자원과 전력, 실시간 요구사항, 내장형 환경 등에 적응해야 하는 시스템입니다. 따라서 임베디드 CPU와 임베디드 GPU는 다음과 같은 특징을 가집니다.
저전력: 임베디드 시스템은 배터리로 작동하거나 전력 소모가 제한된 환경에서 사용되기 때문에, 임베디드 CPU와 임베디드 GPU는 저전력으로 동작해야 합니다. 저전력을 위해 임베디드 CPU와 임베디드 GPU는 저전압, 저주파, 저성능 모드, 동적 전력 관리 등의 기술을 적용합니다.
고성능: 임베디드 시스템은 복잡하고 다양한 작업을 수행하기 때문에, 임베디드 CPU와 임베디드 GPU는 고성능을 제공해야 합니다. 고성능을 위해 임베디드 CPU와 임베디드 GPU는 고주파, 고성능 모드, 멀티코어, 벡터 연산, 병렬 처리 등의 기술을 적용합니다.
실시간성: 임베디드 시스템은 실시간으로 반응하고 제어해야 하는 작업을 수행하기 때문에, 임베디드 CPU와 임베디드 GPU는 실시간성을 보장해야 합니다. 실시간성을 위해 임베디드 CPU와 임베디드 GPU는 고정된 실행 시간, 우선 순위 기반 스케줄링, 인터럽트 처리, 실시간 운영체제 등의 기술을 적용합니다.
내장형: 임베디드 시스템은 작고 특정한 목적을 위해 설계된 환경에서 사용되기 때문에, 임베디드 CPU와 임베디드 GPU는 내장형으로 구현되어야 합니다. 내장형을 위해 임베디드 CPU와 임베디드 GPU는 작고 경량화된 칩, 통합된 메모리, 특정한 인터페이스, 내장형 소프트웨어 등의 기술을 적용합니다.
임베디드 CPU와 임베디드 GPU는 임베디드 시스템의 성능과 효율성을 높이기 위해 협력하거나 독립적으로 작동할 수 있습니다. 임베디드 CPU와 임베디드 GPU의 협력 방식에는 다음과 같은 것들이 있습니다.
CPU-GPU 통합: 임베디드 CPU와 임베디드 GPU를 하나의 칩에 통합하는 방식입니다. 이 방식은 전력 소모와 칩 크기를 줄이고, 데이터 전송과 동기화를 간소화하며, 메모리 공유를 가능하게 합니다. 예를 들어, 인텔의 코어 프로세서나 AMD의 라이젠 프로세서는 CPU와 GPU를 통합한 칩입니다.
CPU-GPU 분리: 임베디드 CPU와 임베디드 GPU를 별도의 칩으로 구현하는 방식입니다. 이 방식은 CPU와 GPU의 성능과 기능을 독립적으로 확장하고, 서로 다른 제조사나 기술을 사용할 수 있게 합니다. 예를 들어, 엔비디아의 젯슨 시리즈나 퀄컴의 스냅드래곤 시리즈는 CPU와 GPU를 분리한 칩입니다.
CPU-GPU 협업: 임베디드 CPU와 임베디드 GPU가 서로 다른 작업을 나눠서 수행하거나, 같은 작업을 병렬로 수행하는 방식입니다. 이 방식은 CPU와 GPU의 각각의 장점을 살리고, 작업의 효율성과 성능을 향상시킵니다. 예를 들어, 오픈클이나 쿠다 같은 프로그래밍 플랫폼은 CPU와 GPU의 협업을 지원합니다.
임베디드 CPU와 임베디드 GPU에 대한 더 많은 정보를 원하신다면, 다음의 웹 검색 결과를 참고하시기 바랍니다.
다만, 임베디드 CPU와 임베디드 GPU의 차이점에 대해 간단하게 설명해드릴 수 있습니다. 임베디드 CPU는 컴퓨터나 임베디드 시스템의 핵심 부품으로, 다양한 명령어를 수행하고, 데이터를 처리하고, 입출력 장치와 통신하는 역할을 합니다. 임베디드 GPU는 컴퓨터나 임베디드 시스템의 그래픽 성능을 향상시키는 부품으로, 이미지, 비디오, 애니메이션 등의 그래픽 관련 작업을 전문적으로 처리하는 역할을 합니다.
임베디드 CPU와 임베디드 GPU는 일반적인 CPU와 GPU와 비슷한 기능을 하지만, 임베디드 시스템에 특화된 특징을 가집니다. 임베디드 시스템은 제한된 자원과 전력, 실시간 요구사항, 내장형 환경 등에 적응해야 하는 시스템입니다. 따라서 임베디드 CPU와 임베디드 GPU는 다음과 같은 특징을 가집니다.
저전력: 임베디드 시스템은 배터리로 작동하거나 전력 소모가 제한된 환경에서 사용되기 때문에, 임베디드 CPU와 임베디드 GPU는 저전력으로 동작해야 합니다. 저전력을 위해 임베디드 CPU와 임베디드 GPU는 저전압, 저주파, 저성능 모드, 동적 전력 관리 등의 기술을 적용합니다.
고성능: 임베디드 시스템은 복잡하고 다양한 작업을 수행하기 때문에, 임베디드 CPU와 임베디드 GPU는 고성능을 제공해야 합니다. 고성능을 위해 임베디드 CPU와 임베디드 GPU는 고주파, 고성능 모드, 멀티코어, 벡터 연산, 병렬 처리 등의 기술을 적용합니다.
실시간성: 임베디드 시스템은 실시간으로 반응하고 제어해야 하는 작업을 수행하기 때문에, 임베디드 CPU와 임베디드 GPU는 실시간성을 보장해야 합니다. 실시간성을 위해 임베디드 CPU와 임베디드 GPU는 고정된 실행 시간, 우선 순위 기반 스케줄링, 인터럽트 처리, 실시간 운영체제 등의 기술을 적용합니다.
내장형: 임베디드 시스템은 작고 특정한 목적을 위해 설계된 환경에서 사용되기 때문에, 임베디드 CPU와 임베디드 GPU는 내장형으로 구현되어야 합니다. 내장형을 위해 임베디드 CPU와 임베디드 GPU는 작고 경량화된 칩, 통합된 메모리, 특정한 인터페이스, 내장형 소프트웨어 등의 기술을 적용합니다.
임베디드 CPU와 임베디드 GPU에 대한 더 많은 정보를 원하신다면, 다음의 웹 검색 결과를 참고하시기 바랍니다.
GPU와 CPU는 둘 다 데이터를 처리하는 마이크로프로세서입니다. 그러나 GPU는 그래픽 관련 작업에 특화되어 있고, CPU는 다양한 작업에 적합합니다. GPU는 수천 개의 작은 코어로 구성되어 병렬 처리에 강점이 있고, CPU는 몇 개의 큰 코어로 구성되어 순차 처리에 강점이 있습니다. 임베디드 시스템에서 GPU와 CPU는 저전력, 고성능, 실시간성, 내장형 등의 특징을 가집니다. GPU와 CPU의 협력 방식에는 CPU-GPU 통합, CPU-GPU 분리, CPU-GPU 협업 등이 있습니다. GPU와 CPU에 대한 더 자세한 정보는 다음의 웹 검색 결과를 참고하시기 바랍니다.
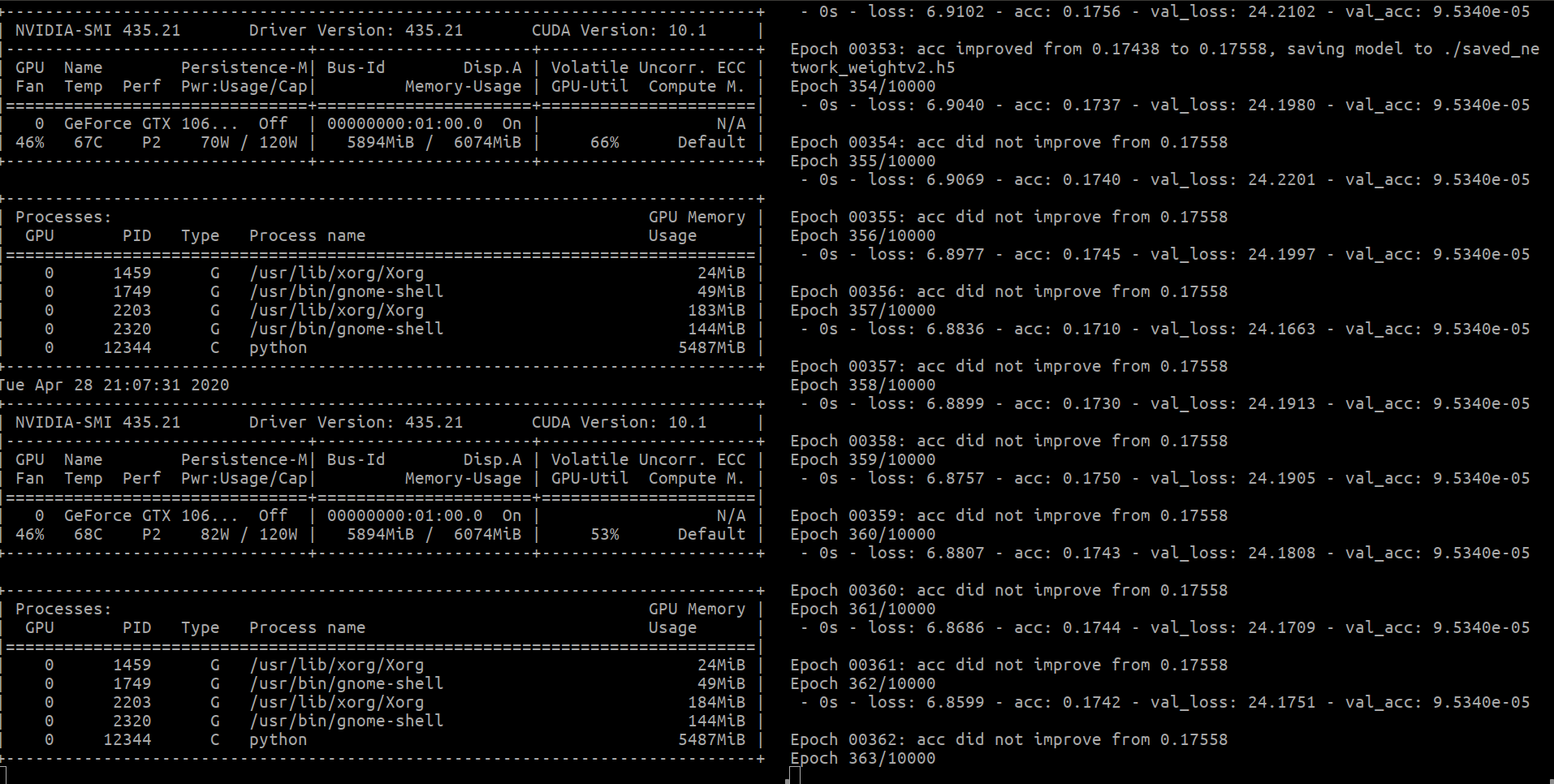
남는 시간에 tensorflow 2.0을 컴파일에 도전했다. 현실은 실패하여 2.1로 목표 재설정. docker 이미지를 사용하면 쉬운데, avx2를 지원하지 않는 CPU를 사용하여 선택할 수 없다. 직접 컴파일하지 않는 한 사용할 수 없다. 최근 개발 이미지를 찾아보니 cuda 10.1, python3 이었다. nvidia-driver는 여러 버전이 설정 되었는데, host pc 버전으로 구동하나 보다. bazel 버전은 3.0이다.
bazel 버전을 2.1.0에 맞는 0.27로 바꿨다. compile 하면 약 6시간 정도 걸린다. 문제가 몇 개 있었다. 전에 램 12GB로 컴파일을 성공했다. 지금 8GB로 해보니, 10,000번 스텝넘어 동작을 멈추고 실패했다. 램을 사기 애매하여 일단 SWAP을 30GB 만들어 컴파일에 성공했다. 그런데 상당히 느리다. 결국 램 8GB를 구매했다. 그런데도 firefox를 띄우고 컴파일하면 에러난다.
메뉴얼은 host에 CUDA를 설치할 필요 없다고 했다. nvidia-driver를 440 버전으로 업데이트 하면 CUDA 10.2를 기본 설치한다. 이게 뭐가 문제냐면 docker gpu 이미지가 10.2을 지원하지 않아 gpu를 사용할 수 없다. 일단 nvidia docker가 10.1 이미지를 띄우면 cuda 10.0으로 내릴 수 없다. 드라이버도 같이 내려야 하는데, 사용 중이어 수정할 수 없나보다. 실패하여 cuda 10.1 이미지를 사용했다. 그러나 nvidia-driver-440으로 cuda 10.1을 사용할 수 없다. 결국 host pc 드라이버를 438로 내렸다.
nvidia driver version 440.82는 CUDA 10.2를 기본 설치한다.
tensorflow 1.12 버전은 host pc driver 440으로 잘 구동한다. 왜 9.0은 실행하는데 10.x 버전을 실행하지 못하는지 모르겠다.
3일째 이 미친 짓을 하고 있다. 뭘 위해서 인지 모르겠다. 지금까지 버린 인건비와 전기 요금을 생각하면 PC 1/3대를 구입했다.
결국 다음 조합으로 컴파일에 성공했다.
ubuntu 18.04
nvidia-driver 435, cuda 10.1
docker image: latest-devel-gpu-py3, cuda 10.1, python 3.
컴파일 거의 마지막 단계에 host python 버전 2와 guest python 버전 3 환경 설정값 다름으로 컴파일을 실패했다. 여기를 참조하여 간단하게 tensorRT를 사용하지 않도록 설정했다. 어차피 내 그래픽 카드는 지원하지 않는다. python2 버전 이미지로 해도 될 듯 하다.
ERROR: /tensorflow_src/tensorflow/tensorflow/python/keras/api/BUILD:129:1: Executing genrule //tensorflow/python/keras/api:keras_python_api_gen_compat_v2 failed (Exit 1)
Traceback (most recent call last):
File "/root/.cache/bazel/_bazel_root/51f904752746bc15a93061eb1cc3b8cc/execroot/org_tensorflow/bazel-out/host/bin/tensorflow/python/keras/api/create_tensorflow.python_api_2_keras_python_api_gen_compat_v2.runfiles/org_tensorflow/tensorflow/python/tools/api/generator/create_python_api.py", line 27, in <module>nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 cuda-npp-10-1 10.1.243-1 [54.9 MB]
Get:9 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 cuda-libraries-10-1 10.1.243-1 [2588 B]
Get:10 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 cuda-nvrtc-dev-10-1 10.1.243-1 [8812 B]
from tensorflow.python.tools.api.generator import doc_srcs
File "/root/.cache/bazel/_bazel_root/51f904752746bc15a93061eb1cc3b8cc/execroot/org_tensorflow/bazel-out/host/bin/tensorflow/python/keras/api/create_tensorflow.python_api_2_keras_python_api_gen_compat_v2.runfiles/org_tensorflow/tensorflow/python/__init__.py", line 85, in <module>
from tensorflow.python.ops.standard_ops import *
File "/root/.cache/bazel/_bazel_root/51f904752746bc15a93061eb1cc3b8cc/execroot/org_tensorflow/bazel-out/host/bin/tensorflow/python/keras/api/create_tensorflow.python_api_2_keras_python_api_gen_compat_v2.runfiles/org_tensorflow/tensorflow/python/ops/standard_ops.py", line 117, in <module>
from tensorflow.python.compiler.tensorrt import trt_convert as trt
File "/root/.cache/bazel/_bazel_root/51f904752746bc15a93061eb1cc3b8cc/execroot/org_tensorflow/bazel-out/host/bin/tensorflow/python/keras/api/create_tensorflow.python_api_2_keras_python_api_gen_compat_v2.runfiles/org_tensorflow/tensorflow/python/compiler/tensorrt/__init__.py", line 22, in <module>
from tensorflow.python.compiler.tensorrt import trt_convert as trt
File "/root/.cache/bazel/_bazel_root/51f904752746bc15a93061eb1cc3b8cc/execroot/org_tensorflow/bazel-out/host/bin/tensorflow/python/keras/api/create_tensorflow.python_api_2_keras_python_api_gen_compat_v2.runfiles/org_tensorflow/tensorflow/python/compiler/tensorrt/trt_convert.py", line 28, in <module>
from tensorflow.compiler.tf2tensorrt import wrap_py_utils
File "/root/.cache/bazel/_bazel_root/51f904752746bc15a93061eb1cc3b8cc/execroot/org_tensorflow/bazel-out/host/bin/tensorflow/python/keras/api/create_tensorflow.python_api_2_keras_python_api_gen_compat_v2.runfiles/org_tensorflow/tensorflow/compiler/tf2tensorrt/wrap_py_utils.py", line 28, in <module>
_wrap_py_utils = swig_import_helper()
File "/root/.cache/bazel/_bazel_root/51f904752746bc15a93061eb1cc3b8cc/execroot/org_tensorflow/bazel-out/host/bin/tensorflow/python/keras/api/create_tensorflow.python_api_2_keras_python_api_gen_compat_v2.runfiles/org_tensorflow/tensorflow/compiler/tf2tensorrt/wrap_py_utils.py", line 24, in swig_import_helper
_mod = imp.load_module('_wrap_py_utils', fp, pathname, description)
File "/usr/lib/python3.6/imp.py", line 243, in load_module
return load_dynamic(name, filename, file)
File "/usr/lib/python3.6/imp.py", line 343, in load_dynamic
return _load(spec)
ImportError: /root/.cache/bazel/_bazel_root/51f904752746bc15a93061eb1cc3b8cc/execroot/org_tensorflow/bazel-out/host/bin/tensorflow/python/keras/api/create_tensorflow.python_api_2_keras_python_api_gen_compat_v2.runfiles/org_tensorflow/tensorflow/compiler/tf2tensorrt/_wrap_py_utils.so: undefined symbol: _ZN15stream_executor14StreamExecutor18EnablePeerAccessToEPS0_
----------------
Note: The failure of target //tensorflow/python/keras/api:create_tensorflow.python_api_2_keras_python_api_gen_compat_v2 (with exit code 1) may have been caused by the fact that it is a Python 2 program that was built in the host configuration, which uses Python 3. You can change the host configuration (for the entire build) to instead use Python 2 by setting --host_force_python=PY2.
If this error started occurring in Bazel 0.27 and later, it may be because the Python toolchain now enforces that targets analyzed as PY2 and PY3 run under a Python 2 and Python 3 interpreter, respectively. See https://github.com/bazelbuild/bazel/issues/7899 for more information.
----------------
Target //tensorflow/tools/pip_package:build_pip_package failed to build
Use --verbose_failures to see the command lines of failed build steps.
INFO: Elapsed time: 26069.299s, Critical Path: 545.35s
INFO: 26668 processes: 26668 local.
FAILED: Build did NOT complete successfully
드디어 2.1 컴파일을 성공했다. 한 번 컴파일 끝내기 위해 7시간씩 썼다. 총 5번은 실패했고 6번째 성공했다. 업데이트 전 제대로 실행됨을 확인했다. update 하고 실행하니 또 에러 뜬다. cuda 10.2 문제임을 여기에서 확인했다. 다시 버전을 내렸다.
2020-04-28 11:13:07.200201: E tensorflow/stream_executor/cuda/cuda_blas.cc:238] failed to create cublas handle: CUBLAS_STATUS_NOT_INITIALIZED
2020-04-28 11:13:07.202605: E tensorflow/stream_executor/cuda/cuda_blas.cc:238] failed to create cublas handle: CUBLAS_STATUS_NOT_INITIALIZED
2020-04-28 11:13:07.202635: W tensorflow/stream_executor/stream.cc:2041] attempting to perform BLAS operation using StreamExecutor without BLAS support
2020-04-28 11:13:07.202674: W tensorflow/core/common_runtime/base_collective_executor.cc:217] BaseCollectiveExecutor::StartAbort Internal: Blas GEMM launch failed : a.shape=(10000, 4), b.shape=(4, 1024), m=10000, n=1024, k=4
[[{{node dense_1/MatMul}}]]
Traceback (most recent call last):
File "200428getSortedValuev3.py", line 198, in <module>
model2.fit(x=fixed_sentence_by_index, y=training_result_asarray, epochs=10000, verbose=2, validation_split=0.3, callbacks=callbacks_list, batch_size=10000, shuffle=True)
File "/usr/local/lib/python3.6/dist-packages/keras/engine/training.py", line 1239, in fit
validation_freq=validation_freq)
File "/usr/local/lib/python3.6/dist-packages/keras/engine/training_arrays.py", line 196, in fit_loop
outs = fit_function(ins_batch)
File "/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/backend.py", line 3727, in __call__
outputs = self._graph_fn(*converted_inputs)
File "/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/eager/function.py", line 1551, in __call__
return self._call_impl(args, kwargs)
File "/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/eager/function.py", line 1591, in _call_impl
return self._call_flat(args, self.captured_inputs, cancellation_manager)
File "/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/eager/function.py", line 1692, in _call_flat
ctx, args, cancellation_manager=cancellation_manager))
File "/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/eager/function.py", line 545, in call
ctx=ctx)
File "/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/eager/execute.py", line 67, in quick_execute
six.raise_from(core._status_to_exception(e.code, message), None)
File "<string>", line 3, in raise_from
tensorflow.python.framework.errors_impl.InternalError: Blas GEMM launch failed : a.shape=(10000, 4), b.shape=(4, 1024), m=10000, n=1024, k=4
[[node dense_1/MatMul (defined at /usr/local/lib/python3.6/dist-packages/keras/backend/tensorflow_backend.py:3009) ]] [Op:__inference_keras_scratch_graph_1128]
Function call stack:
keras_scratch_graph
미국 국방부가 리눅스로 무기 체계를 개발한다고 한다. 오픈소스를 사용하려면 이런 저런 문제점을 모두 직접 해결해야 한다. 정말 없는 길을 만들어 간다. 기업이 왜 오픈소스로 서비스하지 않는지 알 만하다. 구글같은 능력있는 회사정도 되야 오픈소스로 서비스 할 만하다. 누가 오픈소스로 서비스 한다고 하면 능력자라 인식해야겠다.
이것 설치한다고 이틀을 날렸다. 메뉴얼을 제대로 안 읽은 내탓도 있지만, Nvidia가 별다를 설명없이 기존 버전을 숨겨버린 탓도 있다. 멀쩡한 OS도 한번 날리고.
Tensorflow 인스톨 사이트에 아래와 같이 써있다.
NVIDIA requirements to run TensorFlow with GPU support
If you are installing TensorFlow with GPU support using one of the mechanisms described in this guide, then the following NVIDIA software must be installed on your system:
CUDA® Toolkit 8.0. For details, see NVIDIA’s documentation. Ensure that you append the relevant Cuda pathnames to the LD_LIBRARY_PATH environment variable as described in the NVIDIA documentation.
The NVIDIA drivers associated with CUDA Toolkit 8.0.
cuDNN v6. For details, see NVIDIA’s documentation. Ensure that you create the CUDA_HOME environment variable as described in the NVIDIA documentation.
CUDA toolkit : 필히 8.0!! Nvidia 다운로드 사이트에 가면 9.0이 딱 있다. 8.0을 찾을수가 없다. 8.0은 여기에..
cuDNN도 CUDA toolkit 8.0에 맞는 버전을 설치한다.
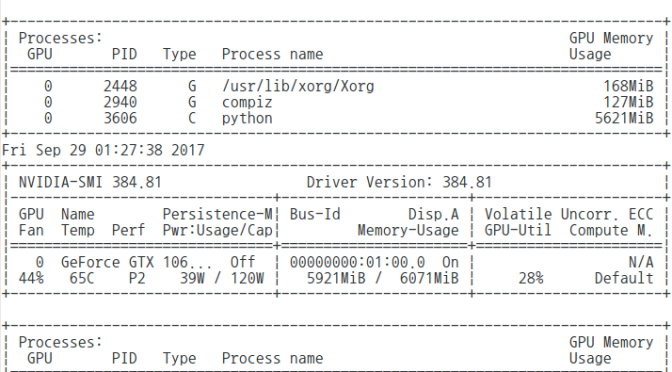
나는 그래픽 드라이버를 384.81 버전을 설치했다. Nvidia 사이트에 최신 드라이버가 있는데, 그 버전 사용하려다 OS를 다시 설치했다. 저장소를 추가하고, sudo apt-get install 이렇게 쉽게 드라이버를 인스톨하면 된다. CUDA toolkit이 드라이버를 업데이트 한다.
비교!
CPU 버전으로 5,000[초/횟수]에 걸쳐하는 작업이, GPU를 사용하면 500[초/횟수]로 0이 하나 줄었다!!
GPU 선정.
싼 GTX 1060 6gb를 사기로 했다. 3gb 메모리 제품이 더 싼데, 사용하는데 문제 된다고 한다. 초심자에겐 값싼 gtx 1060이 최고다.
게다가 PC 케이스가 작아, 1070 이후 제품을 넣으려면 케이스를 뜯어내야 한다. 1060 길이가 260mm인데, 자로 한번 케이스를 재어 보니 좀 여유있게 들어 갈 수 있어 보인다.
메인보드를 한 8년 사용하는데, pciE 2.0과 3.0 차이가 없다고 보고, 그냥 사용하기로 했다. GTX 1060 6gb와 호환 가능
후기.
8년전 PC 살 때, 리누스가 Nvidia에 뽀큐를 날렸다는 말을 듣고, AMD 그래픽 카드를 샀는데….AMD 병신 카드였다. 제품을 만들었으면 드라이버도 좀 신경을 써야 하는데, 영 신경을 안쓴다. 윈도우에서도 그닥이고..내 인생에 다시 AMD 제품을 구매할 일이 없다. Gtx 7이나 8시리즈만 되었어도 그냥 썼을텐데..쩝..