put은 기존에 6번 셀까지 끌어 당겼으나(6번이 A, 7번이 B 표시부, put 동작시 6번은 A->V, 7번은 B->A로 변경되었음), 문제를 쉽게 풀기 위해서 7번 셀만 수정(put 실행시 7번만 B->V로 수정, 7번에 있던 B 대차는 화살표 표시까지 깊게 들어감).
shiftX1, X2, X3 조건 추가.(전체 행동은 기존 get 3개, put 3개, shift X1/X2/X3 3개, getX3Y3 1개 총 10개로 증가)
성공하면 총 점 0점 이상을 획득한다. 100회 샘플 성공, 실패를 세어보면 아래와 같다.
환경설정에서 이번 행동이 의미있는 행동이라면 벌점을 상쇄하고 득점하도록 설정. 이렇게 하면 call만 학습한다!!
최대 삽질 수량을 증가. 단순하게 하면 에피소드를 끝까지 보낼 수 없어 정확하게 판단할 수 없어 보임.
global network 횟수 증가, 한번 업데이트 시 단위 에피소드 감소(100개에서 20개)
성공 리워드를 2,000점, 실패시 -100점, 매 턴마다 -30점 획득 설정.
기존에 최대 성공 800회/최대 1,000회 에서 940번 성공까지 올랐다. 네트웍을 장난질 하면 더 올라갈 수 있어 보인다.
기존 현재 state만 입력으로 받았을 경우현재+과거 state를 입력으로 받았을 경우episode 23은 제대로 했다.
이렇게 하니, Actino.put 동작이 없어졌다. 가산점을 얻기 위해서 get만 실행하는 듯 하다!! 대차가 뒤쪽에 있는 경우(Y1 선) 여전히 삽질한다.
전 시도가 망한 듯 하여 하루동안 다시 학습 시켰다.(20. 12. 18)
현재 상태를 입력 -> 현재 상태, 과거 상태 입력.
네트웍 구조 단순화. 3개 층.
dropout 적용 0.8 적용.
환경설정에서 이번 행동이 의미있는 행동이라면 벌점을 상쇄하고 득점하도록 설정. -> getX1, X2, X3을 했을 경우 nextType과 앞 열 대차가 일치하면 추가 점수 획득. -> DQN 도 연속된 4장 사진을 입력으로 받아들이는데, 중간 행동에 대한 평가를 추가.
최대 삽질 수량을 5로 감소.(전에 8번동안 공대차를 call하고 실패하면 벌점 100점 획득) (단순하게 하면 에피소드를 끝까지 보낼 수 없어 정확하게 판단할 수 없어 보임.)
global network 횟수 증가, 한번 업데이트 시 단위 에피소드 감소(100개에서 20개)
성공했을 경우 reward를 감소. 2,000점에서 200점으로 수정.
1,000회 중 성공 횟수.
성공 점수를 200점으로 내리면 웬만한 문제는 3턴 안에 해결한다.
get과 put이 있는데, put은 포기하고 대부분 대차 순환으로 해결한다.
put을 왜 실행하지 않는지 모르겠다. 가산점을 얻기 위해서인지..
20.12.20. update
왜 put을 안 하는지 알았다. 시스템 설계를 잘못해서 put 없이도 문제를 풀 수 있다. get으로 공간을 만들어 채우면 모두 풀 수 있다! 와!! 똑똑한데… 예상과 다르게 환경 설정함이 어렵다.
하…. 이거 한다고 거의 며칠을 날렸다. A3C 성능이 좋다길래 따라 해 봤는데, 내가 가진 책은 tensorflow 1.x 버전 기준 코드가 실렸다. tensorflow 2.x대로 업데이트 되면서 과거 여러 능력자들이 구현한 fit 부분 코드를 사용할 수 없게 되었다. 대세는 gradienttape()로 네트웍을 업데이트 하는 방법이라고 한다. a3c에서는 local 모델을 global 모델과 똑같이 만들고, local model 경험으로 global network를 업데이트 한다. thread 개수는 임의로 선택한다. a2c 확장편이라 thread 와 apply 부분을 조금 수정하면 쉽게 된다고 생각했다. state로 모델을 예측하는 부분을 틀려서 아래 결과를 얻었다.
2,000번대에 주식을 사서 14,000번대에 팔고 싶다. 주식 차트를 보는 듯 하다. 위 그래프는 에피소드가 끝날 때 까지 새로운 action을 얻어야 했는데, action을 한번만 얻어서 그렇다. 제대로 실행하면 다음 그래프와 같아야 한다. 점수는 임의대로 했다.
from env_reinforcev2 import CarrierStorage
from env_reinforcev2 import Action
import random
from collections import defaultdict
import numpy as np
from termcolor import colored
from keras.models import Sequential
from keras.layers import Dense, Input
from keras.models import Model
from keras.optimizers import Adam
import copy
from keras.models import model_from_json
from collections import deque
from keras import backend as K
import threading
from queue import Queue
import time
from tensorflow.python import keras
import matplotlib.pyplot as plt
eps = np.finfo(np.float32).eps.item() # Smallest number such that 1.0 + eps != 1.0
#여기 참조.
#https://github.com/tensorflow/models/blob/master/research/a3c_blogpost/a3c_cartpole.py
#actor critic 을 따로 만듦.
#https://github.com/marload/DeepRL-TensorFlow2/blob/master/A3C/A3C_Discrete.py
#custom loss를 구하기 위해 tensor를 즉시 확인.
import tensorflow as tf
tf.config.run_functions_eagerly(True)
# 멀티쓰레딩을 위한 글로벌 변수
# 환경 생성
env_name = "smart_storage"
# 브레이크아웃에서의 A3CAgent 클래스(글로벌신경망)
class A3CAgent:
def __init__(self):
# 상태크기와 행동크기를 갖고옴
self.state_size = 40
self.action_size = 7
self.value_size = 1
# A3C 하이퍼파라미터
self.discount_factor = 0.9
#self.actor_lr = 2.5e-4
#self.critic_lr = 2.5e-4
# 쓰레드의 갯수
self.threads = 12
self.DEFINE_NEW = False
self.RENDER = False
#global network 설정
#self.a3c_global_model = ActorCriticModel(self.state_size, self.action_size)
#self.global_actor, self.global_critic = self.a3c_global_model.build_model()
self.global_model = self.build_actorCritic()
def build_actorCritic(self):
if(self.DEFINE_NEW == True):
input = Input(shape = (self.state_size,))
common = Dense(self.state_size*8, activation='relu', kernel_initializer='he_uniform')(input)
common2 = Dense(self.action_size*8, activation = 'relu',kernel_initializer='he_uniform')(common)
common3 = Dense(self.state_size*4, activation='relu', kernel_initializer='he_uniform')(common2)
action_prob = Dense(self.action_size, activation = 'softmax', kernel_initializer='he_uniform')(common3)
critic = Dense(1)(common3)
model = Model(inputs = input, outputs = [action_prob, critic])
else:
#있는 데이터 로딩
json_actor = open("./201208ActorA3c.json", "r")
loaded_actor = json_actor.read()
json_actor.close()
model= model_from_json(loaded_actor)
print("모델 %s를 로딩"%json_actor)
weight_actor = "./201208weightCriticA3c.h5"
model.load_weights(weight_actor)
print("저장된 weights %s를 로딩"%weight_actor)
return model
def get_action(self, action_prob):
#[[확율 형식으로 출력]]
# [0]을 넣어 줌
#print("policy = ", policy)
return np.random.choice(self.action_size, 1, p=np.squeeze(action_prob))[0]
def train(self):
# 쓰레드 수만큼 Agent 클래스 생성
agents = [Agent(self.action_size, self.state_size, self.global_model)
for _ in range(self.threads)]
# 각 쓰레드 시작
for agent in agents:
time.sleep(2)
agent.start()
# 10분(600초)에 한번씩 모델을 저장
while True:
time.sleep(60 * 10)
model_json_actor = self.global_model.to_json()
with open("./201208ActorA3c.json", "w") as json_file:
json_file.write(model_json_actor)
self.global_model.save_weights("./201208weightCriticA3c.h5")
# 액터러너 클래스(쓰레드)
class Agent(threading.Thread):
def __init__(self, action_size, state_size, model):
threading.Thread.__init__(self)
self.action_size = action_size
self.state_size = state_size
# 지정된 타임스텝동안 샘플을 저장할 리스트
self.states, self.actions, self.rewards = [], [], []
#init로 넘어온 global model을 연결.
self.global_model = model
# 로컬 모델 생성
self.local_model = self.build_local_actorCritic()
#global로 업데이트
self.update_local_from_global()
#A3C model class 안에 있는 정보를 밖으로 빼줘야 하는데,
#귀찮아서 그냥 씀.
self.discount_factor = 0.8
self.value_size = 1
#self.avg_p_max = 0
#self.avg_loss = 0
# 모델 업데이트 주기
self.t_max = 20
self.t = 0
def build_local_actorCritic(self):
input = Input(shape = (self.state_size,))
common = Dense(self.state_size*8, activation='relu', kernel_initializer='he_uniform')(input)
common2 = Dense(self.action_size*8, activation = 'relu',kernel_initializer='he_uniform')(common)
common3 = Dense(self.state_size*4, activation='relu', kernel_initializer='he_uniform')(common2)
action_prob = Dense(self.action_size, activation = 'softmax', kernel_initializer='he_uniform')(common3)
critic = Dense(1)(common3)
model = Model(inputs = input, outputs = [action_prob, critic])
return model
def update_local_from_global(self):
self.local_model.set_weights(self.global_model.get_weights())
def run(self):
#메인 함수
env = CarrierStorage()
#agent = A3CAgent()
state = env.reset()
#state history를 기록
#historyState = []
scores, episodes, score_average = [], [], []
EPISODES = 1000000
#EPISODES = 100
global_step = 0
average = 0
huber_loss = tf.losses.Huber()
optimizer = Adam(learning_rate = 0.001)
#action, critic, reward를 list로 기록.
actionprob_history, critic_history, reward_history = [], [], []
total_loss_batch = []
success_counter = 0
success_counter_list = []
for e in range (EPISODES):
#print("episode check", e)
done = False
score = 0
#불가능한 경우가 나오면 다시 reset
#gradient tape에서 0를 넣으면 에러.
while(True):
state = env.reset()
state = env.stateTo1hot(self.state_size)
status = env.isItEnd()
if(status == -1):
break;
#print("reseted")
#if(status == 0 or status == 1):
# done = True
# reward = 0
#print("zero rewards")
#여기에서 apply.gradients를 적용한면 안됨.
#with tf.GradientTape(persistent=True) as tape:
with tf.GradientTape() as tape:
while not done:
action_prob, critic = self.local_model(state)
if(agent.RENDER == True):
env.render()
global_step += 1
#tape 아래로 모델을 입력해야 input, output 관계를 알 수 있음.
#actor, critic 모두 예측.
#action은 action tf.Tensor(
#[[0.16487105 0.0549401 0.12524831 0.1738248 0.31119537 0.07012787 0.0997925 ]], shape=(1, 7), dtype=float32)
#critic은
#critic tf.Tensor([[0.04798129]], shape=(1, 1), dtype=float32)
#으로 출력.
#action_prob로 action을 구함.
action = agent.get_action(action_prob[0])
#print("actionprob history",actionprob_history)
if(agent.RENDER == True):
print("action is", Action(action))
next_state, reward, done, info = env.step(action)
#history에 추가
critic_history.append(critic[0,0])
actionprob_history.append(tf.math.log(action_prob[0, action]))
reward_history.append(reward)
next_state = env.stateTo1hot(agent.state_size)
#_, next_critic = agent.model(next_state)
score += reward
average = average + score
state = copy.deepcopy(next_state)
#score로 성공, 실패 판단.
#print("score", score)
if(score > 0):
success_counter = success_counter + 1
#rewards 를 discounted factor로 다시 계산.
returns = []
discounted_sum = 0
for r in reward_history[::-1]:
discounted_sum = r + agent.discount_factor* discounted_sum
returns.insert(0, discounted_sum)
# Normalize
#returns를 normailze하면
#매 에피소드마다 한 행동이 다른데,
#같은 값으로 맞춤.
#주석 처리.
#reset 과정 중 완료인데 학습루트로 들어가는 경우를 찾아 수정.
#normailze 다시 원복.
#normalize를 사용하면 잘 안되는것 같은. 다시 삭제 후 학습.
#state를 예측하는 부분을 잘못 넣어서 여태까지 다 삽질.
#action_prob, critic = self.local_model(state) 위치 바꾼 뒤 다사 normailze on
returns = np.array(returns)
returns = (returns - np.mean(returns)) / (np.std(returns) + eps)
returns = returns.tolist()
#print("critic history", critic_history)
#print("action prob", action_prob)
#print("return", reward)
# Calculating loss values to update our network
history = zip(actionprob_history, critic_history, returns)
#print("history", history)
actor_losses = []
critic_losses = []
for log_prob, value, ret in history:
advantage = ret - value
#advantage = reward + (1.0 - done) * agent.discount_factor * next_critic - critic
#[ [prob, prob, ... ] ]형식으로 입력이 들어옮
actor_losses.append(-log_prob*advantage)
#critic_losses.append(advantage**2)
critic_losses.append(huber_loss(tf.expand_dims(value, 0), tf.expand_dims(ret, 0)))
#print("actor loss ", actor_losses)
#print("critic loss ", critic_losses)
#모델이 하나라 actor_loss + critic_loss 더해서 한번에 train
#print("grad" , grads)
#print("history", len(actionprob_history))
#print("actor_losses", actor_losses)
total_loss = actor_losses + critic_losses
#print("total loss", total_loss)
#loss도 gradientTape 안에 들어있어야 함.
#print("type total loss", type(total_loss))
#print("total loss", total_loss.numpy())
#10개씩 모아서 학습
total_loss_batch.append(total_loss)
#print("total loss", total_loss)
#print("total loss length", len(total_loss))
#print("total loss batch ", total_loss_batch)
#print("total loss batch length", len(total_loss_batch))
#print("==========================")
#global model update
#print("length", total_loss_batch)
#reinforce는 2000개씩 모아서 학습하는게 효과적인듯 하나.
#a3c는 100개씩 조금씩 잘라서 업데이트를 빨리 하는게 좋아 보임.
#grads = tape.gradient(total_loss_batch, self.local_model.trainable_weights)
#grads = tape.gradient(total_loss, self.local_model.trainable_weights)
if(e%200 == 0 and e> 1):
grads = tape.gradient(total_loss_batch, self.local_model.trainable_weights)
optimizer.apply_gradients(zip(grads, self.global_model.trainable_weights))
self.update_local_from_global()
#print("hit!")
#print("total_loss_batch len is", len(total_loss_batch))
total_loss_batch.clear()
#history clear
actionprob_history.clear()
critic_history.clear()
reward_history.clear()
#if(len(actionprob_history) > 0 & e%10 == 0):
#if(e%100 == 0 and len(total_loss_batch) > 0):
#위에서 done이 없으면 작은 이벤트만 계산함.
#완전하게 다 끝났을 경우에만 학습하기 위해 done을 추가
#print("actor losses", len(actor_losses))
#print("critic losses", len(critic_losses))
#print("check", len(total_loss))
#print("done", done)
#grads = tape.gradient(total_loss, self.local_model.trainable_weights)
# grads = tape.gradient(total_loss_batch, self.local_model.trainable_weights)
#print("grads", grads)
# optimizer.apply_gradients(zip(grads, self.global_model.trainable_weights))
#print("actionprob history", actionprob_history)
#print("cirtic,",critic_history)
#print("rewards", reward_history)
#print("actor losses", len(actor_losses))
#print("critic losses", len(critic_losses))
#print("total loss", len(total_loss))
#print("actionprob_history", len(actionprob_history))
#print("episodes", e)
#global network으로 local network update
#self.update_local_from_global()
#print("hit!")
#print("total loss batch len", len(total_loss_batch))
# total_loss_batch = []
#total_loss_batch.clear()
if(agent.RENDER == True):
print("episode:", e, " score:", score)
if(e%1000 == 0):
#print("history length is", len(actionprob_history))
#print("total loss length is", total_loss.numpy().size)
print("episode:", e, " score:", score, "global_step", global_step,"average", average,
"success_counter", success_counter)
scores.append(score)
success_counter_list.append(success_counter)
score_average.append(average)
episodes.append(e)
#매 1000회마다 average 초기화.
average = 0
#model_json_actor = self.global_model.to_json()
#with open("./201208ActorA3c.json", "w") as json_file:
# json_file.write(model_json_actor)
#self.global_model.save_weights("./201208weightCriticA3c.h5")
#plt.plot(episodes, score_average, 'b')
plt.plot(episodes, success_counter_list, 'b')
success_counter = 0
#plt.show()
plt.savefig("./history.png")
#비어있는 history로 gradients를 계산하지 않도록..
#print("episode", e)
if __name__ == '__main__':
#메인 함수
agent = A3CAgent()
agent.train()
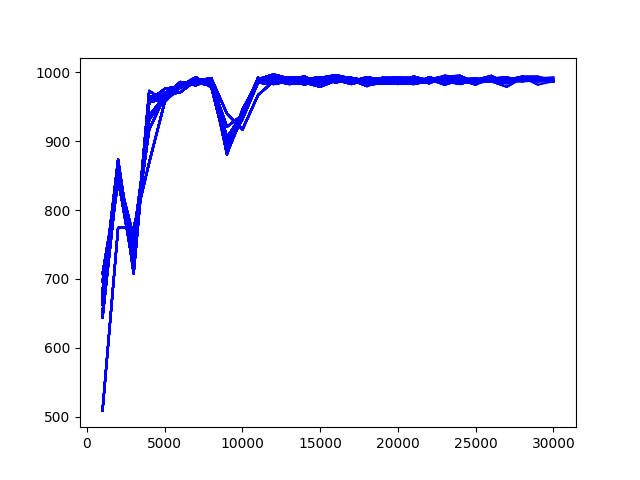
이런저런 테스트를 하다보니 코드가 넝마 조각인데, 다시 수정하긴 귀찮다. 역시 위와 같이 해도, 뒤쪽에 있는 대차를 잘 뽑아내지 못한다. 환경을 상당히 까다롭게 설정해야 한다. 중간에 return을 normailze 하여 학습하는데, normailze를 하지 말아야 할 듯하다. 각 thread 별 값이 다른데, 일정 기준으로 맞추면 각 행동을 제대로 학습시킬 수 없어 보인다. 아래 그래프가 return을 normailze로 한 경우인데, 학습이 잘 안된다. 왼쪽 숫자는 전체 1,000회 중 성공 회수다.
normailze return.
normailze를 하지 않으면 아래 그림과 같다.
하도 여러 사이트에서 가져다 쓰다 보니, 어디에서 무엇을 참조 했는지 모르겠다. 일단 다 적어야겠다.
누군가 열심히 개발한 알고리즘을 개발했다면, 내가 처음 코드를 만든다면 할만하다. 그러나 인터넷에 시간이 남아도는 인간이 많고 그들을 다 제치고 내가 처음이 아닌 확률이 상당히 크다. 누군가 만든 고급진 코드를 충분하게 찾아 볼 필요가 있고, 만약 있다면 다시 할 필요는 없다. 다시해도 그 성능을 넘어설 수 없다. 찾아보니 강화학습을 쉽게 사용할 수 있는 keras-rl을 찾았다. 2.0 버전에 맞도록 구현된 keras-rl2를 설치하면 된다.
python -m pip install keras-rl2
사용자는 각자에 필요한 환경을 설정하면 된다. 사용자가 이 부분에서 삽질해야 하고, 가치 있다. opanai-gym은 인공지능 알고리즘을 쉽게 개발하기 위해 설정한 환경이고, keras-rl은 누군가 개발한 알고리즘을 쉽게 사용하기 위한 방법이다. 각자 환경을 openai-gym 형식에 맞춰 넣으면 된다. 다음 tutorial을 보면 된다.
dqn, a2c 등 유명한 알고리즘을 구현했다. 내가 필요한 a3c을 구현할 때 까지 기다리면 된다.
튜토리얼을 돌리면 에러난다. display가 제대로 설정되지 않았다. 내가 필요한 환경에서는 굳이 display가 필요없다.
tf-docker /home/mnt/keras-rl > python test.py
2020-11-07 23:00:09.425948: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 4) 0
_________________________________________________________________
dense (Dense) (None, 16) 80
_________________________________________________________________
activation (Activation) (None, 16) 0
_________________________________________________________________
dense_1 (Dense) (None, 16) 272
_________________________________________________________________
activation_1 (Activation) (None, 16) 0
_________________________________________________________________
dense_2 (Dense) (None, 16) 272
_________________________________________________________________
activation_2 (Activation) (None, 16) 0
_________________________________________________________________
dense_3 (Dense) (None, 2) 34
_________________________________________________________________
activation_3 (Activation) (None, 2) 0
=================================================================
Total params: 658
Trainable params: 658
Non-trainable params: 0
_________________________________________________________________
None
2020-11-07 23:00:10.496021: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcuda.so.1
2020-11-07 23:00:10.510795: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-11-07 23:00:10.511178: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1716] Found device 0 with properties:
pciBusID: 0000:26:00.0 name: GeForce GTX 1060 6GB computeCapability: 6.1
coreClock: 1.7085GHz coreCount: 10 deviceMemorySize: 5.93GiB deviceMemoryBandwidth: 178.99GiB/s
2020-11-07 23:00:10.511203: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
2020-11-07 23:00:10.512417: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcublas.so.10
2020-11-07 23:00:10.513603: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcufft.so.10
2020-11-07 23:00:10.513800: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcurand.so.10
2020-11-07 23:00:10.515074: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcusolver.so.10
2020-11-07 23:00:10.515803: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcusparse.so.10
2020-11-07 23:00:10.518627: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudnn.so.7
2020-11-07 23:00:10.518842: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-11-07 23:00:10.519243: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-11-07 23:00:10.519566: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1858] Adding visible gpu devices: 0
2020-11-07 23:00:10.519919: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN)to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2020-11-07 23:00:10.542963: I tensorflow/core/platform/profile_utils/cpu_utils.cc:104] CPU Frequency: 3399500000 Hz
2020-11-07 23:00:10.543724: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x52a1590 initialized for platform Host (this does not guarantee that XLA will be used). Devices:
2020-11-07 23:00:10.543767: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version
2020-11-07 23:00:10.799878: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-11-07 23:00:10.800523: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x4baece0 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices:
2020-11-07 23:00:10.800604: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): GeForce GTX 1060 6GB, Compute Capability 6.1
2020-11-07 23:00:10.801142: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-11-07 23:00:10.802326: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1716] Found device 0 with properties:
pciBusID: 0000:26:00.0 name: GeForce GTX 1060 6GB computeCapability: 6.1
coreClock: 1.7085GHz coreCount: 10 deviceMemorySize: 5.93GiB deviceMemoryBandwidth: 178.99GiB/s
2020-11-07 23:00:10.802405: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
2020-11-07 23:00:10.802461: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcublas.so.10
2020-11-07 23:00:10.802499: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcufft.so.10
2020-11-07 23:00:10.802542: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcurand.so.10
2020-11-07 23:00:10.802582: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcusolver.so.10
2020-11-07 23:00:10.802620: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcusparse.so.10
2020-11-07 23:00:10.802660: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudnn.so.7
2020-11-07 23:00:10.802864: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-11-07 23:00:10.803808: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-11-07 23:00:10.804611: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1858] Adding visible gpu devices: 0
2020-11-07 23:00:10.804690: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
2020-11-07 23:00:11.184178: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1257] Device interconnect StreamExecutor with strength 1 edge matrix:
2020-11-07 23:00:11.184228: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1263] 0
2020-11-07 23:00:11.184238: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1276] 0: N
2020-11-07 23:00:11.184452: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-11-07 23:00:11.184839: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-11-07 23:00:11.185183: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1402] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 4853 MB memory) -> physical GPU (device: 0, name: GeForce GTX 1060 6GB, pci bus id: 0000:26:00.0, compute capability: 6.1)
Training for 50000 steps ...
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/training_v1.py:2070: Model.state_updates (from tensorflow.python.keras.engine.training) is deprecated and will be removed in a future version.
Instructions for updating:
This property should not be used in TensorFlow 2.0, as updates are applied automatically.
2020-11-07 23:00:11.519149: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcublas.so.10
Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/gym/envs/classic_control/rendering.py", line 25, in <module>
from pyglet.gl import *
File "/usr/local/lib/python3.6/dist-packages/pyglet/gl/__init__.py", line 95, in <module>
from pyglet.gl.lib import GLException
File "/usr/local/lib/python3.6/dist-packages/pyglet/gl/lib.py", line 149, in <module>
from pyglet.gl.lib_glx import link_GL, link_GLU, link_GLX
File "/usr/local/lib/python3.6/dist-packages/pyglet/gl/lib_glx.py", line 45, in <module>
gl_lib = pyglet.lib.load_library('GL')
File "/usr/local/lib/python3.6/dist-packages/pyglet/lib.py", line 164, in load_library
raise ImportError('Library "%s" not found.' % names[0])
ImportError: Library "GL" not found.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "test.py", line 45, in <module>
dqn.fit(env, nb_steps=50000, visualize=True, verbose=2)
File "/usr/local/lib/python3.6/dist-packages/rl/core.py", line 187, in fit
callbacks.on_action_end(action)
File "/usr/local/lib/python3.6/dist-packages/rl/callbacks.py", line 100, in on_action_end
callback.on_action_end(action, logs=logs)
File "/usr/local/lib/python3.6/dist-packages/rl/callbacks.py", line 362, in on_action_end
self.env.render(mode='human')
File "/usr/local/lib/python3.6/dist-packages/gym/core.py", line 240, in render
return self.env.render(mode, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/gym/envs/classic_control/cartpole.py", line 174, in render
from gym.envs.classic_control import rendering
File "/usr/local/lib/python3.6/dist-packages/gym/envs/classic_control/rendering.py", line 32, in <module>
''')
ImportError:
Error occurred while running `from pyglet.gl import *`
HINT: make sure you have OpenGL install. On Ubuntu, you can run 'apt-get install python-opengl'.
If you're running on a server, you may need a virtual frame buffer; something like this should work:
'xvfb-run -s "-screen 0 1400x900x24" python <your_script.py>'
a2c를 keras로 사용하려면 loss function을 새롭게 정의해야 한다. 보통 fit으로 넘어오는 인자가 input, output 각 한 개씩 사용한다. input이나 output으로 파라미터를 넘길 때 advantage를 같이 넘겨야 한다. tensorflow 1.x에서는 이게 꼼수로 되었는데, 2.x로 올라오면서 안된다. 아래 보면 actor loss가 0으로 고정되어 있다.
입력 파라미터를 넘길 때 리스트로 2개를 넘길 수 있다. input = [input, advantage] 형식으로 사용할 수 있다. 그러나 tensor를 그대로 넘길 경우 값을 알 수 없어 에러가 난다.
File "/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/execute.py", line 60, in quick_execute
inputs, attrs, num_outputs)
TypeError: An op outside of the function building code is being passed
a "Graph" tensor. It is possible to have Graph tensors
leak out of the function building context by including a
tf.init_scope in your function building code.
For example, the following function will fail:
@tf.function
def has_init_scope():
my_constant = tf.constant(1.)
with tf.init_scope():
added = my_constant * 2
The graph tensor has name: input_2:0
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "agent_a2c.py", line 153, in <module>
agent.train_model(state, action, reward, next_state, done )
File "agent_a2c.py", line 110, in train_model
self.actor.fit(x=[state, advantageTmp], y=actions, epochs = 1, verbose =0)
File "/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/training.py", line 108, in _method_wrapper
return method(self, *args, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/training.py", line 1098, in fit
tmp_logs = train_function(iterator)
File "/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/def_function.py", line 780, in __call__
result = self._call(*args, **kwds)
File "/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/def_function.py", line 840, in _call
return self._stateless_fn(*args, **kwds)
File "/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/function.py", line 2829, in __call__
return graph_function._filtered_call(args, kwargs) # pylint: disable=protected-access
File "/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/function.py", line 1848, in _filtered_call
cancellation_manager=cancellation_manager)
File "/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/function.py", line 1924, in _call_flat
ctx, args, cancellation_manager=cancellation_manager))
File "/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/function.py", line 550, in call
ctx=ctx)
File "/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/execute.py", line 74, in quick_execute
"tensors, but found {}".format(keras_symbolic_tensors))
tensorflow.python.eager.core._SymbolicException: Inputs to eager execution function cannot be Keras symbolic tensors, but found [<tf.Tensor 'input_2:0' shape=(None, 1) dtype=float32>]
이럴 경우 eager.execution을 넣어주면 에러를 없앨 수 있다. tensorflow 2.x부터 추가되었다.
from env_reinforce import CarrierStorage
from env_reinforce import Action
import random
from collections import defaultdict
import numpy as np
from termcolor import colored
from keras.models import Sequential
from keras.layers import Dense, Input
from keras.models import Model
from keras.optimizers import Adam
import copy
from keras.models import model_from_json
from collections import deque
from keras import backend as K
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
#custom loss를 구하기 위해 tensor를 즉시 확인.
import tensorflow as tf
tf.config.experimental_run_functions_eagerly(True)
class A2CAgent(object):
def __init__(self):
#단순하게 했을 경우에는 40으로 사용.
self.state_size = 40 #float value 하나 사용
self.action_size = 7
self.value_size = 1
self.discount_factor = 0.99
self.actor_lr = 0.001
self.critic_lr = 0.005
self.actor = self.build_actor()
self.critic = self.build_critic()
# actor: 상태를 받아 각 행동의 확률을 계산
def build_actor(self):
input = Input(shape = (self.state_size,))
delta = Input(shape = [1])
print("delta is ", delta)
dense1 = Dense(self.state_size*2, activation='relu', kernel_initializer='he_uniform')(input)
action = Dense(self.action_size, activation = 'softmax', kernel_initializer='he_uniform')(dense1)
actor = Model(inputs = [input, delta], outputs = action)
def actor_loss(y_true, y_prediction):
out = K.clip(y_prediction, 1e-8, 1-1e-8)
log_likily = y_true*K.log(out)
return K.sum(-log_likily * delta)
actor.summary()
#loss function이 문제..
actor.compile(loss = actor_loss, optimizer = Adam(lr=self.actor_lr))
return actor
# critic: 상태를 받아서 상태의 가치를 계산
def build_critic(self):
critic = Sequential()
critic.add(Dense(self.state_size*2, input_dim=self.state_size, activation='relu', kernel_initializer='he_uniform'))
#critic.add(Dense(24, input_dim=self.state_size, activation='relu', kernel_initializer='he_uniform'))
critic.add(Dense(self.value_size, activation='linear', kernel_initializer='he_uniform'))
critic.compile(loss = 'mse', optimizer = Adam(lr=self.critic_lr))
print("critic summary")
critic.summary()
return critic
# 각 타임스텝마다 정책신경망과 가치신경망을 업데이트
def train_model(self, state, action, reward, next_state, done):
value = self.critic.predict(state)[0][0]
next_value = self.critic.predict(next_state)[0][0]
#action을 one-hot 으로 만듦.
actions = np.zeros([1, self.action_size])
actions[np.arange(1), action] = 1.0
#reshape
actions = np.reshape(actions, [1, self.action_size])
# 벨만 기대 방정식를 이용한 어드벤티지와 업데이트 타깃
if done:
advantage = reward - value
target = reward
else:
advantage = (reward + self.discount_factor * next_value) - value
target = reward + self.discount_factor * next_value
#tensorflow 2.3, keras 2.4에 맞도록 수정.
#np.array를 추가해야 함.
target = np.reshape(target, [1,self.value_size])
#print("target shape is", target.shape)
#critic을 predictionr과 target으로 업데이트
self.critic.fit(state, target, epochs = 1, verbose = 0)
advantageTmp = np.reshape(advantage, [1,1])
self.actor.fit(x=[state, advantageTmp], y=actions, epochs = 1, verbose =0)
def get_action(self, state):
#[[확율 형식으로 출력]]
# [0]을 넣어 줌
policy = self.actor.predict(state)[0]
#print("policy = ", policy)
return np.random.choice(self.action_size, 1, p=policy)[0]
if __name__ == '__main__':
#메인 함수
env = CarrierStorage()
agent = A2CAgent()
state = env.reset()
#state history를 기록
#historyState = []
scores, episodes = [], []
EPISODES = 1000
global_step = 0
for e in range (EPISODES):
done = False
score = 0
state = env.reset()
state = env.stateTo1hot(agent.state_size)
status = env.isItEnd()
if(status == 0 or status == 1):
done = True
reward = 0
while not done:
#env.render()
global_step += 1
action = agent.get_action(state)
#print("action is", Action(action))
next_state, reward, done, info = env.step(action)
next_state = env.stateTo1hot(agent.state_size)
agent.train_model(state, action, reward, next_state, done )
score += reward
state = copy.deepcopy(next_state)
if done:
print("episode:", e, " score:", score, "global_step", global_step)
scores.append(score)
episodes.append(e)
plt.plot(episodes, scores, 'b')
plt.show()
plt.savefig("./history.png")
뭐가 잘 안맞는지, 1,000회 학습하면 별 효과가 없다. 각 100번째 평균을 보면 다음과 같다. 경험 리플레이를 사용하지 않은 것과 같은 현상이다. A3C로 고고!
tf-docker /home/mnt/myStorage/test_gradientTape > python testCustomLoss.py
2020-11-18 16:00:53.764598: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
2020-11-18 16:00:54.659858: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcuda.so.1
2020-11-18 16:00:54.678468: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-11-18 16:00:54.678865: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1716] Found device 0 with properties:
pciBusID: 0000:26:00.0 name: GeForce GTX 1060 6GB computeCapability: 6.1
coreClock: 1.7085GHz coreCount: 10 deviceMemorySize: 5.93GiB deviceMemoryBandwidth: 178.99GiB/s
2020-11-18 16:00:54.678890: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
2020-11-18 16:00:54.680022: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcublas.so.10
2020-11-18 16:00:54.681178: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcufft.so.10
2020-11-18 16:00:54.681346: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcurand.so.10
2020-11-18 16:00:54.682446: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcusolver.so.10
2020-11-18 16:00:54.683116: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcusparse.so.10
2020-11-18 16:00:54.685549: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudnn.so.7
2020-11-18 16:00:54.685688: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-11-18 16:00:54.686097: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-11-18 16:00:54.686405: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1858] Adding visible gpu devices: 0
2020-11-18 16:00:54.686688: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN)to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2020-11-18 16:00:54.710941: I tensorflow/core/platform/profile_utils/cpu_utils.cc:104] CPU Frequency: 3399500000 Hz
2020-11-18 16:00:54.711710: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x41b63d0 initialized for platform Host (this does not guarantee that XLA will be used). Devices:
2020-11-18 16:00:54.711754: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version
2020-11-18 16:00:54.986824: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-11-18 16:00:54.987296: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x41b8620 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices:
2020-11-18 16:00:54.987352: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): GeForce GTX 1060 6GB, Compute Capability 6.1
2020-11-18 16:00:54.987771: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-11-18 16:00:54.988673: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1716] Found device 0 with properties:
pciBusID: 0000:26:00.0 name: GeForce GTX 1060 6GB computeCapability: 6.1
coreClock: 1.7085GHz coreCount: 10 deviceMemorySize: 5.93GiB deviceMemoryBandwidth: 178.99GiB/s
2020-11-18 16:00:54.988743: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
2020-11-18 16:00:54.988804: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcublas.so.10
2020-11-18 16:00:54.988846: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcufft.so.10
2020-11-18 16:00:54.988887: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcurand.so.10
2020-11-18 16:00:54.988926: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcusolver.so.10
2020-11-18 16:00:54.988972: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcusparse.so.10
2020-11-18 16:00:54.989018: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudnn.so.7
2020-11-18 16:00:54.989196: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-11-18 16:00:54.990189: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-11-18 16:00:54.991068: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1858] Adding visible gpu devices: 0
2020-11-18 16:00:54.991140: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
2020-11-18 16:00:55.378048: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1257] Device interconnect StreamExecutor with strength 1 edge matrix:
2020-11-18 16:00:55.378099: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1263] 0
2020-11-18 16:00:55.378107: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1276] 0: N
2020-11-18 16:00:55.378324: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-11-18 16:00:55.378869: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-11-18 16:00:55.379209: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1402] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 4990 MB memory) -> physical GPU (device: 0, name: GeForce GTX 1060 6GB, pci bus id: 0000:26:00.0, compute capability: 6.1)
Model: "functional_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
main_input (InputLayer) [(None, 10)] 0
__________________________________________________________________________________________________
dense (Dense) (None, 4) 44 main_input[0][0]
__________________________________________________________________________________________________
aux_input (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
main_output (Dense) (None, 1) 5 dense[0][0]
==================================================================================================
Total params: 49
Trainable params: 49
Non-trainable params: 0
__________________________________________________________________________________________________
main in (1, 10)
main out (1, 1)
aux input (1, 1)
/usr/local/lib/python3.6/dist-packages/tensorflow/python/data/ops/dataset_ops.py:3350: UserWarning: Even though the tf.config.experimental_run_functions_eagerly option is set, this option does not apply to tf.data functions. tf.data functions are still traced and executed as graphs.
"Even though the tf.config.experimental_run_functions_eagerly "
Epoch 1/10
2020-11-18 16:00:55.511115: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcublas.so.10
1/1 [==============================] - 0s 428us/step - loss: 0.0000e+00
Epoch 2/10
1/1 [==============================] - 0s 331us/step - loss: 0.0000e+00
Epoch 3/10
1/1 [==============================] - 0s 333us/step - loss: 0.0000e+00
Epoch 4/10
1/1 [==============================] - 0s 303us/step - loss: 0.0000e+00
Epoch 5/10
1/1 [==============================] - 0s 302us/step - loss: 0.0000e+00
Epoch 6/10
1/1 [==============================] - 0s 277us/step - loss: 0.0000e+00
Epoch 7/10
1/1 [==============================] - 0s 348us/step - loss: 0.0000e+00
Epoch 8/10
1/1 [==============================] - 0s 289us/step - loss: 0.0000e+00
Epoch 9/10
1/1 [==============================] - 0s 275us/step - loss: 0.0000e+00
Epoch 10/10
1/1 [==============================] - 0s 269us/step - loss: 0.0000e+00
tf-docker /home/mnt/myStorage/test_gradientTape >
혹시나 해서 loss function 안에 변수 대신 숫자를 넣어보니 loss가 변했다. tensorflow 2.x에서는 fit으로 할 수 있을까라는 마음을 접고, 2.x이 지원하는 gradient tape로 해야 할 듯 하다. 다행히 누가 이미 구현했다.
20.11.21. 삽질 끝에 왜 gradient tape으로 업데이트 할 수 없는지 알았다. gradientTape()을 사용한 뒤, model로 입력을 집어 넣어야 한다. 분리되어 있으면 얘가 알 수 없다 에러난다. 코드는 넝마 조각이 되가고 있다. 아직도 한번 함정에 빠지면 빠져 나올 수 없다. 여러 샘플을 수집하여 한번에 학습시켜야 할 듯 하다.
from env_reinforce import CarrierStorage
from env_reinforce import Action
import random
from collections import defaultdict
import numpy as np
from termcolor import colored
from keras.models import Sequential
from keras.layers import Dense, Input
from keras.models import Model
from keras.optimizers import Adam
import copy
from keras.models import model_from_json
from collections import deque
from keras import backend as K
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
#custom loss를 구하기 위해 tensor를 즉시 확인.
import tensorflow as tf
tf.config.run_functions_eagerly(True)
#여기 참조
#https://github.com/keras-team/keras-io/blob/master/examples/rl/actor_critic_cartpole.py
class A2CAgent(object):
def __init__(self):
#단순하게 했을 경우에는 40으로 사용.
self.state_size = 40 #float value 하나 사용
self.action_size = 7
self.discount_factor = 0.99
self.actor_lr = 0.001
self.critic_lr = 0.005
self.DEFINE_NEW = True
self.RENDER = True
#self.actor = self.build_actor()
#self.critic = self.build_critic()
self.model = self.build_actorCritic()
def build_actorCritic(self):
input = Input(shape = (self.state_size,))
common = Dense(self.state_size*2, activation='relu', kernel_initializer='he_uniform')(input)
action_prob = Dense(self.action_size, activation = 'softmax', kernel_initializer='he_uniform')(common)
critic = Dense(1)(common)
model = Model(inputs = input, outputs = [action_prob, critic])
return model
def get_action(self, action_prob):
#[[확율 형식으로 출력]]
# [0]을 넣어 줌
#print("policy = ", policy)
return np.random.choice(self.action_size, 1, p=np.squeeze(action_prob))[0]
if __name__ == '__main__':
#메인 함수
env = CarrierStorage()
agent = A2CAgent()
state = env.reset()
#state history를 기록
#historyState = []
scores, episodes, score_average = [], [], []
EPISODES = 100000
global_step = 0
average = 0
for e in range (EPISODES):
done = False
score = 0
state = env.reset()
state = env.stateTo1hot(agent.state_size)
status = env.isItEnd()
if(status == 0 or status == 1):
done = True
reward = 0
while not done:
if(agent.RENDER == True):
env.render()
global_step += 1
with tf.GradientTape() as tape:
#tape 아래로 모델을 입력해야 input, output 관계를 알 수 있음.
#actor, critic 모두 예측.
action_prob, critic = agent.model(state)
#numpy state를 tensor로 바꾸고, overide한 call로 입력.
#state = np.reshape(state, [1, agent.state_size])
#state = tf.convert_to_tensor(state, dtype=tf.int8, dtype_hint=None, name=None)
#action_prob, critic = agent.model.call(state)
print("action prob", action_prob)
#print("critic", critic)
#action은 action tf.Tensor(
#[[0.16487105 0.0549401 0.12524831 0.1738248 0.31119537 0.07012787 0.0997925 ]], shape=(1, 7), dtype=float32)
#critic은
#critic tf.Tensor([[0.04798129]], shape=(1, 1), dtype=float32)
#으로 출력.
#action_prob로 action을 구함.
action = agent.get_action(action_prob[0])
#print("Action is", Action(action))
#
#print("critic", critic)
#print("next critic", next_critic)
if(agent.RENDER == True):
print("action is", Action(action))
next_state, reward, done, info = env.step(action)
next_state = env.stateTo1hot(agent.state_size)
_, next_critic = agent.model(next_state)
advantage = reward + (1.0 - done) * agent.discount_factor * next_critic - critic
#[ [prob, prob, ... ] ]형식으로 입력이 들어옮
actor_loss = tf.math.log(action_prob[0, action]) * advantage
critic_loss = advantage**2
print("actor loss ", actor_loss)
print("critic loss ", critic_loss)
#모델이 하나라 actor_loss + critic_loss 더해서 한번에 train
total_loss = actor_loss + critic_loss
grads = tape.gradient(total_loss, agent.model.trainable_weights)
#print("grad" , grads)
optimizer = Adam(learning_rate = 0.01)
optimizer.apply_gradients(zip(grads, agent.model.trainable_weights))
score += reward
average = average + score
state = copy.deepcopy(next_state)
if done:
if(agent.RENDER == True):
print("episode:", e, " score:", score)
if(e%1000 == 0 and e>1):
print("episode:", e, " score:", score, "global_step", global_step,"average", average)
scores.append(score)
score_average.append(average)
episodes.append(e)
#매 100회마다 average 초기화.
average = 0
model_json_actor = agent.model.to_json()
model_json_critic = agent.model.to_json()
with open("./201027ActorA2c.json", "w") as json_file:
json_file.write(model_json_actor)
with open("./201027CriticA2c.json", "w") as json_file:
json_file.write(model_json_critic)
agent.model.save_weights("./201027weightActorA2c.h5")
agent.model.save_weights("./201027weightCriticA2c.h5")
plt.plot(episodes, score_average, 'b')
#plt.show()
plt.savefig("./history.png")
tensorflow 2.x이 fit을 지원하지 않고 gradientTape로 학습시켜야 하여 좀 불편하다. 나온지 오래되어 여러 꼼수들을 써먹을 수 없다. 수정하고 수정하여 아래와 같이 했다. 점수는 DQN보다 잘 안오르는 편이다. 100개씩 샘플을 저장하여 학습시켰는데, 총점이 1000점 넘기기 힘들다. 그래도 점수가 오르락 내리락 하는 패턴을 보면 알고리즘은 정확한 듯 하다. gradientTape 안에 넣을 때 loss 구하는 부분도 같은 탭에 있어야 한다. 잘 몰라 한참 해멨다.
from env_reinforce import CarrierStorage
from env_reinforce import Action
import random
from collections import defaultdict
import numpy as np
from termcolor import colored
from keras.models import Sequential
from keras.layers import Dense, Input
from keras.models import Model
from keras.optimizers import Adam
import copy
from keras.models import model_from_json
from collections import deque
from keras import backend as K
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
eps = np.finfo(np.float32).eps.item() # Smallest number such that 1.0 + eps != 1.0
#custom loss를 구하기 위해 tensor를 즉시 확인.
import tensorflow as tf
tf.config.run_functions_eagerly(True)
#여기 참조
#https://github.com/keras-team/keras-io/blob/master/examples/rl/actor_critic_cartpole.py
class A2CAgent(object):
def __init__(self):
#단순하게 했을 경우에는 40으로 사용.
self.state_size = 40 #float value 하나 사용
self.action_size = 7
self.discount_factor = 0.8
self.DEFINE_NEW = False
self.RENDER = False
#self.actor = self.build_actor()
#self.critic = self.build_critic()
self.model = self.build_actorCritic()
def build_actorCritic(self):
if(self.DEFINE_NEW == True):
input = Input(shape = (self.state_size,))
common = Dense(self.state_size*24, activation='relu', kernel_initializer='he_uniform')(input)
common2 = Dense(self.action_size*12, activation = 'relu',kernel_initializer='he_uniform')(common)
action_prob = Dense(self.action_size, activation = 'softmax', kernel_initializer='he_uniform')(common2)
critic = Dense(1)(common2)
model = Model(inputs = input, outputs = [action_prob, critic])
else:
#있는 데이터 로딩
json_actor = open("./201027ActorA2c.json", "r")
loaded_actor = json_actor.read()
json_actor.close()
model= model_from_json(loaded_actor)
print("모델 %s를 로딩"%json_actor)
weight_actor = "./201027weightCriticA2c.h5"
model.load_weights(weight_actor)
print("저장된 weights %s를 로딩"%weight_actor)
return model
def get_action(self, action_prob):
#[[확율 형식으로 출력]]
# [0]을 넣어 줌
#print("policy = ", policy)
return np.random.choice(self.action_size, 1, p=np.squeeze(action_prob))[0]
if __name__ == '__main__':
#메인 함수
env = CarrierStorage()
agent = A2CAgent()
state = env.reset()
#state history를 기록
#historyState = []
scores, episodes, score_average = [], [], []
EPISODES = 100000
global_step = 0
average = 0
huber_loss = tf.losses.Huber()
optimizer = Adam(learning_rate = 0.0001)
#action, critic, reward를 list로 기록.
actionprob_history, critic_history, reward_history = [], [], []
for e in range (EPISODES):
#print("episode check", e)
done = False
score = 0
state = env.reset()
state = env.stateTo1hot(agent.state_size)
status = env.isItEnd()
#print("reseted")
if(status == 0 or status == 1):
done = True
reward = 0
#print("zero rewards")
#여기에서 apply.gradients를 적용한면 안됨.
while not done:
if(agent.RENDER == True):
env.render()
global_step += 1
#tape 아래로 모델을 입력해야 input, output 관계를 알 수 있음.
#actor, critic 모두 예측.
#with tf.GradientTape(persistent=True) as tape:
with tf.GradientTape() as tape:
action_prob, critic = agent.model(state)
#action은 action tf.Tensor(
#[[0.16487105 0.0549401 0.12524831 0.1738248 0.31119537 0.07012787 0.0997925 ]], shape=(1, 7), dtype=float32)
#critic은
#critic tf.Tensor([[0.04798129]], shape=(1, 1), dtype=float32)
#으로 출력.
#action_prob로 action을 구함.
action = agent.get_action(action_prob[0])
#print("actionprob history",actionprob_history)
if(agent.RENDER == True):
print("action is", Action(action))
next_state, reward, done, info = env.step(action)
#history에 추가
critic_history.append(critic[0,0])
actionprob_history.append(tf.math.log(action_prob[0, action]))
reward_history.append(reward)
next_state = env.stateTo1hot(agent.state_size)
#_, next_critic = agent.model(next_state)
score += reward
average = average + score
state = copy.deepcopy(next_state)
#rewards 를 discounted factor로 다시 계산.
returns = []
discounted_sum = 0
for r in reward_history[::-1]:
discounted_sum = r + agent.discount_factor* discounted_sum
returns.insert(0, discounted_sum)
# Normalize
returns = np.array(returns)
returns = (returns - np.mean(returns)) / (np.std(returns) + eps)
returns = returns.tolist()
# Calculating loss values to update our network
history = zip(actionprob_history, critic_history, returns)
actor_losses = []
critic_losses = []
for log_prob, value, ret in history:
advantage = ret - value
#advantage = reward + (1.0 - done) * agent.discount_factor * next_critic - critic
#[ [prob, prob, ... ] ]형식으로 입력이 들어옮
actor_losses.append(-log_prob*advantage)
#critic_losses.append(advantage**2)
critic_losses.append(huber_loss(tf.expand_dims(value, 0), tf.expand_dims(ret, 0)))
#print("actor loss ", actor_losses)
#print("critic loss ", critic_losses)
#모델이 하나라 actor_loss + critic_loss 더해서 한번에 train
#print("grad" , grads)
#print("history", len(actionprob_history))
total_loss = actor_losses + critic_losses
#loss도 gradientTape 안에 들어있어야 함.
if(len(actionprob_history) > 0 ):
#print("actor losses", len(actor_losses))
#print("critic losses", len(critic_losses))
#print("check", len(total_loss))
grads = tape.gradient(total_loss, agent.model.trainable_weights)
#print("grads", grads)
optimizer.apply_gradients(zip(grads, agent.model.trainable_weights))
#print("actionprob history", actionprob_history)
#print("cirtic,",critic_history)
#print("rewards", reward_history)
#print("actor losses", len(actor_losses))
#print("critic losses", len(critic_losses))
#print("total loss", len(total_loss))
#print("actionprob_history", len(actionprob_history))
#print("episodes", e)
if(agent.RENDER == True):
print("episode:", e, " score:", score)
if(e%100 == 0):
print("history length is", len(actionprob_history))
print("episode:", e, " score:", score, "global_step", global_step,"average", average)
scores.append(score)
score_average.append(average)
episodes.append(e)
#매 1000회마다 average 초기화.
average = 0
model_json_actor = agent.model.to_json()
with open("./201027ActorA2c.json", "w") as json_file:
json_file.write(model_json_actor)
agent.model.save_weights("./201027weightCriticA2c.h5")
plt.plot(episodes, score_average, 'b')
#plt.show()
plt.savefig("./history.png")
#비어있는 history로 gradients를 계산하지 않도록..
#print("episode", e)
actionprob_history.clear()
critic_history.clear()
reward_history.clear()
plt.plot(episodes, score_average, 'b')
#plt.show()
plt.savefig("./history.png")
쉬운 작업은 잘 해내어 점수를 내는데, 대차가 구석에 처박혀 있으면 삽질만 하다 점수를 모두 까 먹는다. DQN보다 성능이 낮다. 이제 대망의 A3C로 고고.