blas gemm launch failed tensorflow 2.0
전에 어떻게 해결했는지 모르겠지만, gtx 1060에 model prediction 을 실행하면 BLAS GEMM 어쩌구 나온다. 아래와 같이 cuda 버전 문제이다.
전에 어떻게 해결했는지 모르겠지만, gtx 1060에 model prediction 을 실행하면 BLAS GEMM 어쩌구 나온다. 아래와 같이 cuda 버전 문제이다.
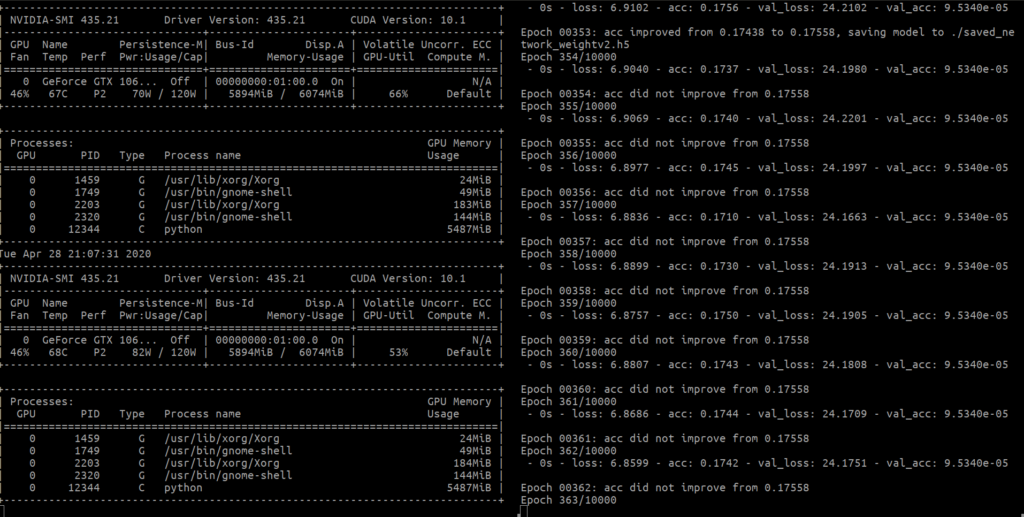
남는 시간에 tensorflow 2.0을 컴파일에 도전했다. 현실은 실패하여 2.1로 목표 재설정. docker 이미지를 사용하면 쉬운데, avx2를 지원하지 않는 CPU를 사용하여
최근 몇 일간 태그를 제한하는 스크립트, 코드를 작성했다. 프로세스는 좀 복잡하다. 시운전자마다 태그를 지멋대로 작성한다. 태그를 잘 분석하면 좋은데, 지
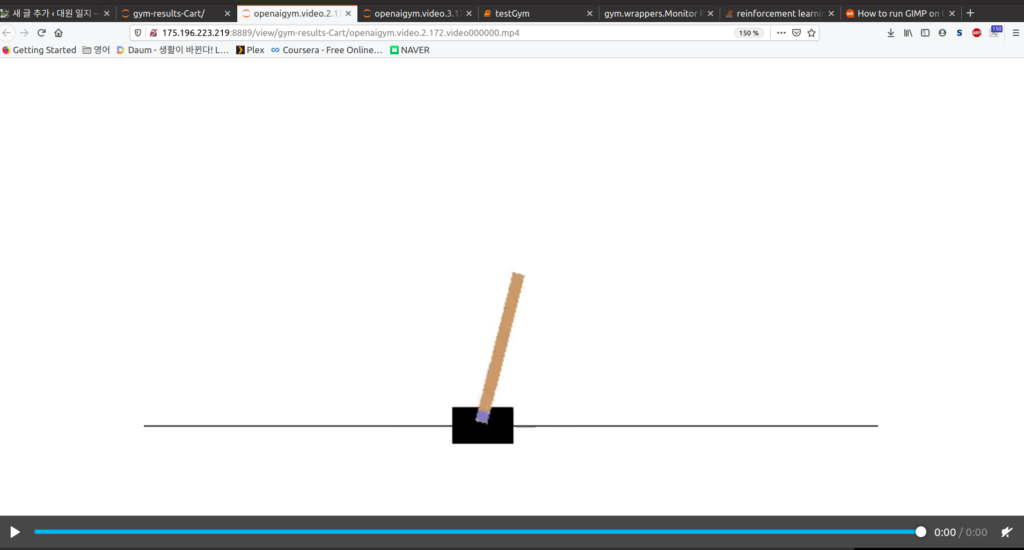
PC를 거실에 설치하고 docker로 tensorflow를 설정했다. docker가 쉽고 간편하여 다 좋은데 그래픽 사용자 인터페이스를 지원하지 않는다. gym을 설정하기 어렵다. 찾다보니
정말 간단한 LSTM으로 정확도 80%대까지 올렸다. 23,000개 데이터를 7,000번 학습시겼다. 정확하게 하려면 모든 카테고리 데이터를 동일하게 맞추고, 내부 태그를 정확하게