과거 acc를 못 올리는 이유를 알아보았다. 둘 중 하나를 선택하는 문제는 activation softmax대신 sigmoid를 사용해야 한다. 아래로 고치고 1,000번 학습시켰다. 최고값을 찾은 weight를 파일로 저장했다. 147번 학습해보니 0.99?? 정확도를 보이나, vlaidation 체크용은 0.87대 정확도를 보인다.
from konlpy.tag import Okt
okt=Okt()
from gensim.models import Word2Vec
from keras.layers import Dense, Flatten, SimpleRNN
from keras.models import Sequential
from keras.preprocessing.sequence import pad_sequences
from keras.layers.embeddings import Embedding
import numpy as np
#model save
from keras.callbacks import ModelCheckpoint
model=Word2Vec.load('./myModel')
MAX_VOCAB=len(model.wv.vocab)
WV_SIZE=model.wv.vectors.shape[1]
print("로드한 모델 vocab 최대값은", MAX_VOCAB)
print("로드한 모델 vectror 크기는", WV_SIZE)
#b=model.wv.most_similar(positive=["클램프", "잠김"])
print(model)
#print(model.wv["후드힌지시프트"])
#tokenizer 설정.
#Okt()사용.
targetFile = open("./tagv4태그붙인파일.csv", "r", encoding='UTF-8')
i=0
sentence_by_index=[]
traing_result=[]
WORD_MAX=6
#WV_SIZE=10
#model을 load후 최대값 확인
#MAX_VOCAB=3532
#못찾은 단어를 입력하기 위한 부분.
#삭제.
#VACANT_ARRAY = np.zeros((4,1))
while True:
lines = targetFile.readline()
firstColumn = lines.split(',')
#print(lines)
if not lines:break
#if i == 1000:break
i=i+1
#word2vec를 만든 형태소 분석기를 사용..
tokenlist = okt.pos(firstColumn[1], stem=True, norm=True)
temp=[]
for word in tokenlist:
#word[0]은 단어.
#word[1]은 품사.
#print("word[0]은",word[0])
#print("word[1]은",word[1])
if word[1] in ["Noun","Alpha","Number"]:
#temp.append(model.wv[word[0]])
#word[0]를 index로 변경.
#단어장에 없는 단어를 예외처리
#입력과 출력을 같이 맞추기 위해, 입출력 동시에 append
try:
#print("---------")
#print(i)
#print(word[0])
temp.append(model.wv.vocab.get(word[0]).index)
#print(model.wv.vocab.get(word[0]).index)
except AttributeError:
#값을 못찾으면 0값 입력
temp.append(0)
#print(temp)
#print("index is ", i)
#print("temp is", temp)
#가져단 쓴 코드는 temp에 값이 있을 경우에만 append.
#출력과 맞추기 위해, list가 비어있어도 append로 변경.
#if temp:
# sentence_by_index.append(temp)
sentence_by_index.append(temp)
#결과를 배열로 입력
tempResult=firstColumn[4].strip('\n')
traing_result.append(tempResult)
targetFile.close()
training_result_asarray = np.asarray(traing_result)
#최대 단어를 6으로 설정.
#행 수보다 6까지 뒤쪽으로 0을 채움.
#word2Vec가 실수이므로 float32로 설정
#result가 embedding_matrix
fixed_sentence_by_index = pad_sequences(sentence_by_index, maxlen=WORD_MAX, padding='post', dtype='int')
print("입력 시퀀스는", fixed_sentence_by_index.shape)
print("출력 시퀀스는", training_result_asarray.shape)
#print("index로 변경한 값은",fixed_sentence_by_index)
#print("embedding vector는", model.wv.vectors)
#keras 모델 설정.
model2= Sequential()
model2.add(Embedding(input_dim=MAX_VOCAB, output_dim=WV_SIZE, input_length=WORD_MAX, weights=[model.wv.vectors], trainable=False))
#model2.add(Flatten())
model2.add(SimpleRNN(128, input_shape=(4,4)))
model2.add(Dense(1, activation='sigmoid'))
model2.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
#save model 경로.
weight_path = "./saved_network_weight.h5"
checkpoint = ModelCheckpoint(weight_path, monitor='acc', verbose=2, save_best_only=True, mode='auto')
callbacks_list = [checkpoint]
model2.fit(x=fixed_sentence_by_index, y=training_result_asarray, epochs=10, verbose=1, validation_split=0.2, callbacks=callbacks_list)
model2.summary()
#input_predict =model.wv.vocab.get(word[0]).index
num0 = model.wv.vocab.get("B").index
num1 = model.wv.vocab.get("180").index
num2 = model.wv.vocab.get("셔틀").index
num3 = model.wv.vocab.get("불간섭").index
input_predict = np.asarray([[num0, num1, num2, num3, 0, 0]])
#print("input_predict 는",input_predict.shape)
myPrediction = model2.predict_classes(input_predict, batch_size=10, verbose=1)
myPredictionAcc = model2.predict(input_predict, batch_size=10, verbose=1)
print("내 예상", myPrediction, "with ", myPredictionAcc)
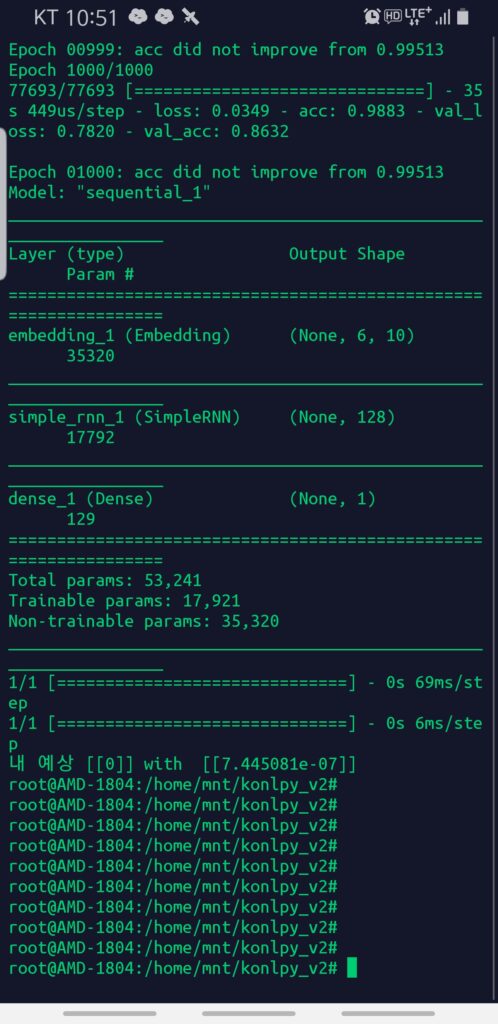
1,000회 하는데 4~5시간정도 걸린 듯 하다. 그러나 불행하게도 weight는 초기에 한번 업데이트하고 말아버렸다. 그래도 이렇게 간단한 구조인데도 87%를 유지하니 좀 파보면 나아질 듯 하다.
이제 입력을 받아들여 이를 판정하는 부분을 만들어 보자.