하…. 이거 한다고 거의 며칠을 날렸다. A3C 성능이 좋다길래 따라 해 봤는데, 내가 가진 책은 tensorflow 1.x 버전 기준 코드가 실렸다. tensorflow 2.x대로 업데이트 되면서 과거 여러 능력자들이 구현한 fit 부분 코드를 사용할 수 없게 되었다. 대세는 gradienttape()로 네트웍을 업데이트 하는 방법이라고 한다. a3c에서는 local 모델을 global 모델과 똑같이 만들고, local model 경험으로 global network를 업데이트 한다. thread 개수는 임의로 선택한다. a2c 확장편이라 thread 와 apply 부분을 조금 수정하면 쉽게 된다고 생각했다. state로 모델을 예측하는 부분을 틀려서 아래 결과를 얻었다.
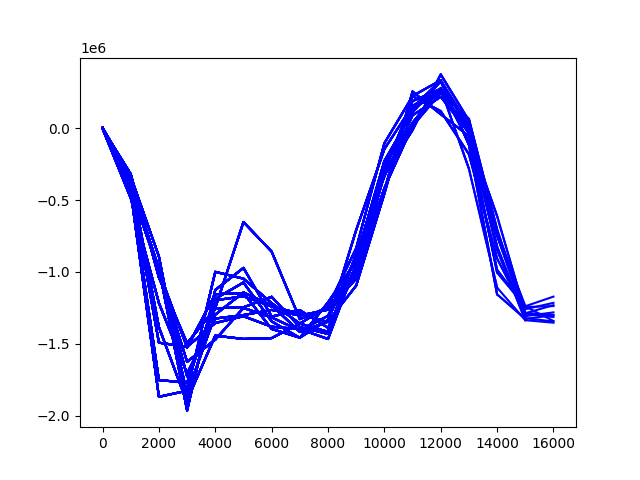
2,000번대에 주식을 사서 14,000번대에 팔고 싶다. 주식 차트를 보는 듯 하다. 위 그래프는 에피소드가 끝날 때 까지 새로운 action을 얻어야 했는데, action을 한번만 얻어서 그렇다. 제대로 실행하면 다음 그래프와 같아야 한다. 점수는 임의대로 했다.
from env_reinforcev2 import CarrierStorage
from env_reinforcev2 import Action
import random
from collections import defaultdict
import numpy as np
from termcolor import colored
from keras.models import Sequential
from keras.layers import Dense, Input
from keras.models import Model
from keras.optimizers import Adam
import copy
from keras.models import model_from_json
from collections import deque
from keras import backend as K
import threading
from queue import Queue
import time
from tensorflow.python import keras
import matplotlib.pyplot as plt
eps = np.finfo(np.float32).eps.item() # Smallest number such that 1.0 + eps != 1.0
#여기 참조.
#https://github.com/tensorflow/models/blob/master/research/a3c_blogpost/a3c_cartpole.py
#actor critic 을 따로 만듦.
#https://github.com/marload/DeepRL-TensorFlow2/blob/master/A3C/A3C_Discrete.py
#custom loss를 구하기 위해 tensor를 즉시 확인.
import tensorflow as tf
tf.config.run_functions_eagerly(True)
# 멀티쓰레딩을 위한 글로벌 변수
# 환경 생성
env_name = "smart_storage"
# 브레이크아웃에서의 A3CAgent 클래스(글로벌신경망)
class A3CAgent:
def __init__(self):
# 상태크기와 행동크기를 갖고옴
self.state_size = 40
self.action_size = 7
self.value_size = 1
# A3C 하이퍼파라미터
self.discount_factor = 0.9
#self.actor_lr = 2.5e-4
#self.critic_lr = 2.5e-4
# 쓰레드의 갯수
self.threads = 12
self.DEFINE_NEW = False
self.RENDER = False
#global network 설정
#self.a3c_global_model = ActorCriticModel(self.state_size, self.action_size)
#self.global_actor, self.global_critic = self.a3c_global_model.build_model()
self.global_model = self.build_actorCritic()
def build_actorCritic(self):
if(self.DEFINE_NEW == True):
input = Input(shape = (self.state_size,))
common = Dense(self.state_size*8, activation='relu', kernel_initializer='he_uniform')(input)
common2 = Dense(self.action_size*8, activation = 'relu',kernel_initializer='he_uniform')(common)
common3 = Dense(self.state_size*4, activation='relu', kernel_initializer='he_uniform')(common2)
action_prob = Dense(self.action_size, activation = 'softmax', kernel_initializer='he_uniform')(common3)
critic = Dense(1)(common3)
model = Model(inputs = input, outputs = [action_prob, critic])
else:
#있는 데이터 로딩
json_actor = open("./201208ActorA3c.json", "r")
loaded_actor = json_actor.read()
json_actor.close()
model= model_from_json(loaded_actor)
print("모델 %s를 로딩"%json_actor)
weight_actor = "./201208weightCriticA3c.h5"
model.load_weights(weight_actor)
print("저장된 weights %s를 로딩"%weight_actor)
return model
def get_action(self, action_prob):
#[[확율 형식으로 출력]]
# [0]을 넣어 줌
#print("policy = ", policy)
return np.random.choice(self.action_size, 1, p=np.squeeze(action_prob))[0]
def train(self):
# 쓰레드 수만큼 Agent 클래스 생성
agents = [Agent(self.action_size, self.state_size, self.global_model)
for _ in range(self.threads)]
# 각 쓰레드 시작
for agent in agents:
time.sleep(2)
agent.start()
# 10분(600초)에 한번씩 모델을 저장
while True:
time.sleep(60 * 10)
model_json_actor = self.global_model.to_json()
with open("./201208ActorA3c.json", "w") as json_file:
json_file.write(model_json_actor)
self.global_model.save_weights("./201208weightCriticA3c.h5")
# 액터러너 클래스(쓰레드)
class Agent(threading.Thread):
def __init__(self, action_size, state_size, model):
threading.Thread.__init__(self)
self.action_size = action_size
self.state_size = state_size
# 지정된 타임스텝동안 샘플을 저장할 리스트
self.states, self.actions, self.rewards = [], [], []
#init로 넘어온 global model을 연결.
self.global_model = model
# 로컬 모델 생성
self.local_model = self.build_local_actorCritic()
#global로 업데이트
self.update_local_from_global()
#A3C model class 안에 있는 정보를 밖으로 빼줘야 하는데,
#귀찮아서 그냥 씀.
self.discount_factor = 0.8
self.value_size = 1
#self.avg_p_max = 0
#self.avg_loss = 0
# 모델 업데이트 주기
self.t_max = 20
self.t = 0
def build_local_actorCritic(self):
input = Input(shape = (self.state_size,))
common = Dense(self.state_size*8, activation='relu', kernel_initializer='he_uniform')(input)
common2 = Dense(self.action_size*8, activation = 'relu',kernel_initializer='he_uniform')(common)
common3 = Dense(self.state_size*4, activation='relu', kernel_initializer='he_uniform')(common2)
action_prob = Dense(self.action_size, activation = 'softmax', kernel_initializer='he_uniform')(common3)
critic = Dense(1)(common3)
model = Model(inputs = input, outputs = [action_prob, critic])
return model
def update_local_from_global(self):
self.local_model.set_weights(self.global_model.get_weights())
def run(self):
#메인 함수
env = CarrierStorage()
#agent = A3CAgent()
state = env.reset()
#state history를 기록
#historyState = []
scores, episodes, score_average = [], [], []
EPISODES = 1000000
#EPISODES = 100
global_step = 0
average = 0
huber_loss = tf.losses.Huber()
optimizer = Adam(learning_rate = 0.001)
#action, critic, reward를 list로 기록.
actionprob_history, critic_history, reward_history = [], [], []
total_loss_batch = []
success_counter = 0
success_counter_list = []
for e in range (EPISODES):
#print("episode check", e)
done = False
score = 0
#불가능한 경우가 나오면 다시 reset
#gradient tape에서 0를 넣으면 에러.
while(True):
state = env.reset()
state = env.stateTo1hot(self.state_size)
status = env.isItEnd()
if(status == -1):
break;
#print("reseted")
#if(status == 0 or status == 1):
# done = True
# reward = 0
#print("zero rewards")
#여기에서 apply.gradients를 적용한면 안됨.
#with tf.GradientTape(persistent=True) as tape:
with tf.GradientTape() as tape:
while not done:
action_prob, critic = self.local_model(state)
if(agent.RENDER == True):
env.render()
global_step += 1
#tape 아래로 모델을 입력해야 input, output 관계를 알 수 있음.
#actor, critic 모두 예측.
#action은 action tf.Tensor(
#[[0.16487105 0.0549401 0.12524831 0.1738248 0.31119537 0.07012787 0.0997925 ]], shape=(1, 7), dtype=float32)
#critic은
#critic tf.Tensor([[0.04798129]], shape=(1, 1), dtype=float32)
#으로 출력.
#action_prob로 action을 구함.
action = agent.get_action(action_prob[0])
#print("actionprob history",actionprob_history)
if(agent.RENDER == True):
print("action is", Action(action))
next_state, reward, done, info = env.step(action)
#history에 추가
critic_history.append(critic[0,0])
actionprob_history.append(tf.math.log(action_prob[0, action]))
reward_history.append(reward)
next_state = env.stateTo1hot(agent.state_size)
#_, next_critic = agent.model(next_state)
score += reward
average = average + score
state = copy.deepcopy(next_state)
#score로 성공, 실패 판단.
#print("score", score)
if(score > 0):
success_counter = success_counter + 1
#rewards 를 discounted factor로 다시 계산.
returns = []
discounted_sum = 0
for r in reward_history[::-1]:
discounted_sum = r + agent.discount_factor* discounted_sum
returns.insert(0, discounted_sum)
# Normalize
#returns를 normailze하면
#매 에피소드마다 한 행동이 다른데,
#같은 값으로 맞춤.
#주석 처리.
#reset 과정 중 완료인데 학습루트로 들어가는 경우를 찾아 수정.
#normailze 다시 원복.
#normalize를 사용하면 잘 안되는것 같은. 다시 삭제 후 학습.
#state를 예측하는 부분을 잘못 넣어서 여태까지 다 삽질.
#action_prob, critic = self.local_model(state) 위치 바꾼 뒤 다사 normailze on
returns = np.array(returns)
returns = (returns - np.mean(returns)) / (np.std(returns) + eps)
returns = returns.tolist()
#print("critic history", critic_history)
#print("action prob", action_prob)
#print("return", reward)
# Calculating loss values to update our network
history = zip(actionprob_history, critic_history, returns)
#print("history", history)
actor_losses = []
critic_losses = []
for log_prob, value, ret in history:
advantage = ret - value
#advantage = reward + (1.0 - done) * agent.discount_factor * next_critic - critic
#[ [prob, prob, ... ] ]형식으로 입력이 들어옮
actor_losses.append(-log_prob*advantage)
#critic_losses.append(advantage**2)
critic_losses.append(huber_loss(tf.expand_dims(value, 0), tf.expand_dims(ret, 0)))
#print("actor loss ", actor_losses)
#print("critic loss ", critic_losses)
#모델이 하나라 actor_loss + critic_loss 더해서 한번에 train
#print("grad" , grads)
#print("history", len(actionprob_history))
#print("actor_losses", actor_losses)
total_loss = actor_losses + critic_losses
#print("total loss", total_loss)
#loss도 gradientTape 안에 들어있어야 함.
#print("type total loss", type(total_loss))
#print("total loss", total_loss.numpy())
#10개씩 모아서 학습
total_loss_batch.append(total_loss)
#print("total loss", total_loss)
#print("total loss length", len(total_loss))
#print("total loss batch ", total_loss_batch)
#print("total loss batch length", len(total_loss_batch))
#print("==========================")
#global model update
#print("length", total_loss_batch)
#reinforce는 2000개씩 모아서 학습하는게 효과적인듯 하나.
#a3c는 100개씩 조금씩 잘라서 업데이트를 빨리 하는게 좋아 보임.
#grads = tape.gradient(total_loss_batch, self.local_model.trainable_weights)
#grads = tape.gradient(total_loss, self.local_model.trainable_weights)
if(e%200 == 0 and e> 1):
grads = tape.gradient(total_loss_batch, self.local_model.trainable_weights)
optimizer.apply_gradients(zip(grads, self.global_model.trainable_weights))
self.update_local_from_global()
#print("hit!")
#print("total_loss_batch len is", len(total_loss_batch))
total_loss_batch.clear()
#history clear
actionprob_history.clear()
critic_history.clear()
reward_history.clear()
#if(len(actionprob_history) > 0 & e%10 == 0):
#if(e%100 == 0 and len(total_loss_batch) > 0):
#위에서 done이 없으면 작은 이벤트만 계산함.
#완전하게 다 끝났을 경우에만 학습하기 위해 done을 추가
#print("actor losses", len(actor_losses))
#print("critic losses", len(critic_losses))
#print("check", len(total_loss))
#print("done", done)
#grads = tape.gradient(total_loss, self.local_model.trainable_weights)
# grads = tape.gradient(total_loss_batch, self.local_model.trainable_weights)
#print("grads", grads)
# optimizer.apply_gradients(zip(grads, self.global_model.trainable_weights))
#print("actionprob history", actionprob_history)
#print("cirtic,",critic_history)
#print("rewards", reward_history)
#print("actor losses", len(actor_losses))
#print("critic losses", len(critic_losses))
#print("total loss", len(total_loss))
#print("actionprob_history", len(actionprob_history))
#print("episodes", e)
#global network으로 local network update
#self.update_local_from_global()
#print("hit!")
#print("total loss batch len", len(total_loss_batch))
# total_loss_batch = []
#total_loss_batch.clear()
if(agent.RENDER == True):
print("episode:", e, " score:", score)
if(e%1000 == 0):
#print("history length is", len(actionprob_history))
#print("total loss length is", total_loss.numpy().size)
print("episode:", e, " score:", score, "global_step", global_step,"average", average,
"success_counter", success_counter)
scores.append(score)
success_counter_list.append(success_counter)
score_average.append(average)
episodes.append(e)
#매 1000회마다 average 초기화.
average = 0
#model_json_actor = self.global_model.to_json()
#with open("./201208ActorA3c.json", "w") as json_file:
# json_file.write(model_json_actor)
#self.global_model.save_weights("./201208weightCriticA3c.h5")
#plt.plot(episodes, score_average, 'b')
plt.plot(episodes, success_counter_list, 'b')
success_counter = 0
#plt.show()
plt.savefig("./history.png")
#비어있는 history로 gradients를 계산하지 않도록..
#print("episode", e)
if __name__ == '__main__':
#메인 함수
agent = A3CAgent()
agent.train()
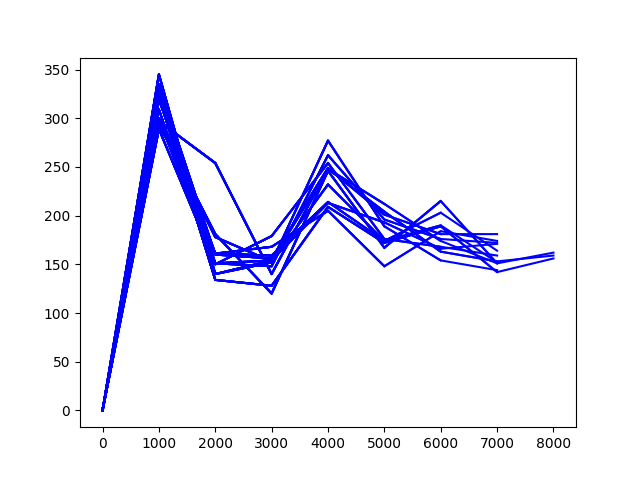
이런저런 테스트를 하다보니 코드가 넝마 조각인데, 다시 수정하긴 귀찮다. 역시 위와 같이 해도, 뒤쪽에 있는 대차를 잘 뽑아내지 못한다. 환경을 상당히 까다롭게 설정해야 한다. 중간에 return을 normailze 하여 학습하는데, normailze를 하지 말아야 할 듯하다. 각 thread 별 값이 다른데, 일정 기준으로 맞추면 각 행동을 제대로 학습시킬 수 없어 보인다. 아래 그래프가 return을 normailze로 한 경우인데, 학습이 잘 안된다. 왼쪽 숫자는 전체 1,000회 중 성공 회수다.
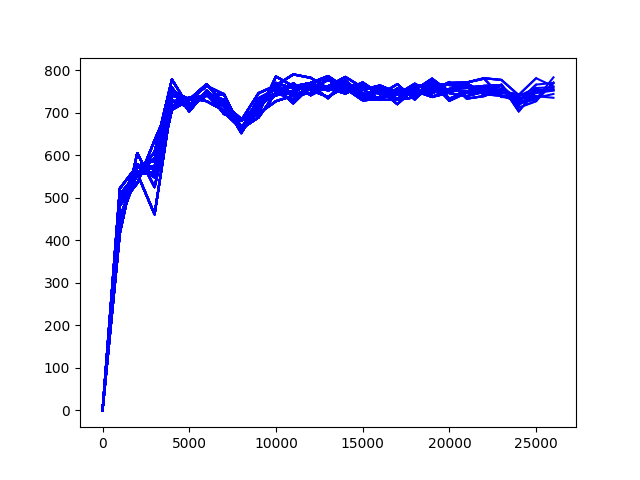
normailze를 하지 않으면 아래 그림과 같다.
하도 여러 사이트에서 가져다 쓰다 보니, 어디에서 무엇을 참조 했는지 모르겠다. 일단 다 적어야겠다.
https://blog.tensorflow.org/2018/07/deep-reinforcement-learning-keras-eager-execution.html
https://rlzoo.readthedocs.io/en/latest/_modules/rlzoo/algorithms/a3c/a3c.html
https://stackoverflow.com/questions/60510441/implementing-a3c-on-tensorflow-2
https://github.com/tensorflow/models/blob/master/research/a3c_blogpost/a3c_cartpole.py
https://github.com/keras-team/keras-io/blob/master/examples/rl/actor_critic_cartpole.py
youtube 쉬운 강의..중간에 매직을 볼 수 있음.
https://github.com/marload/DeepRL-TensorFlow2/blob/master/A3C/A3C_Discrete.py
actor critic 간단한 예제