기존 실험 환경에 문제 있음을 알고, 큰 결심으로 환경을 다시 설정했다.
- 총 Action은 getX1, getX2, getX3, putX1, putX2, putX3, getX3Y3(순환) 7개 였다.
- putX1, putX2, putX3는 2열로만 갈 수 있어, 깊게 들어가 있는 1열을 사용할 수 없었다.
- 인공지능이 삽질로 getX1, getX3, getX3, getX3Y3 으로만 모든 문제를 해결한다!!(나는 몰랐던 사실. 이 사실로 환경이 잘못 디자인되었다고 알았다.)
수정한 환경.
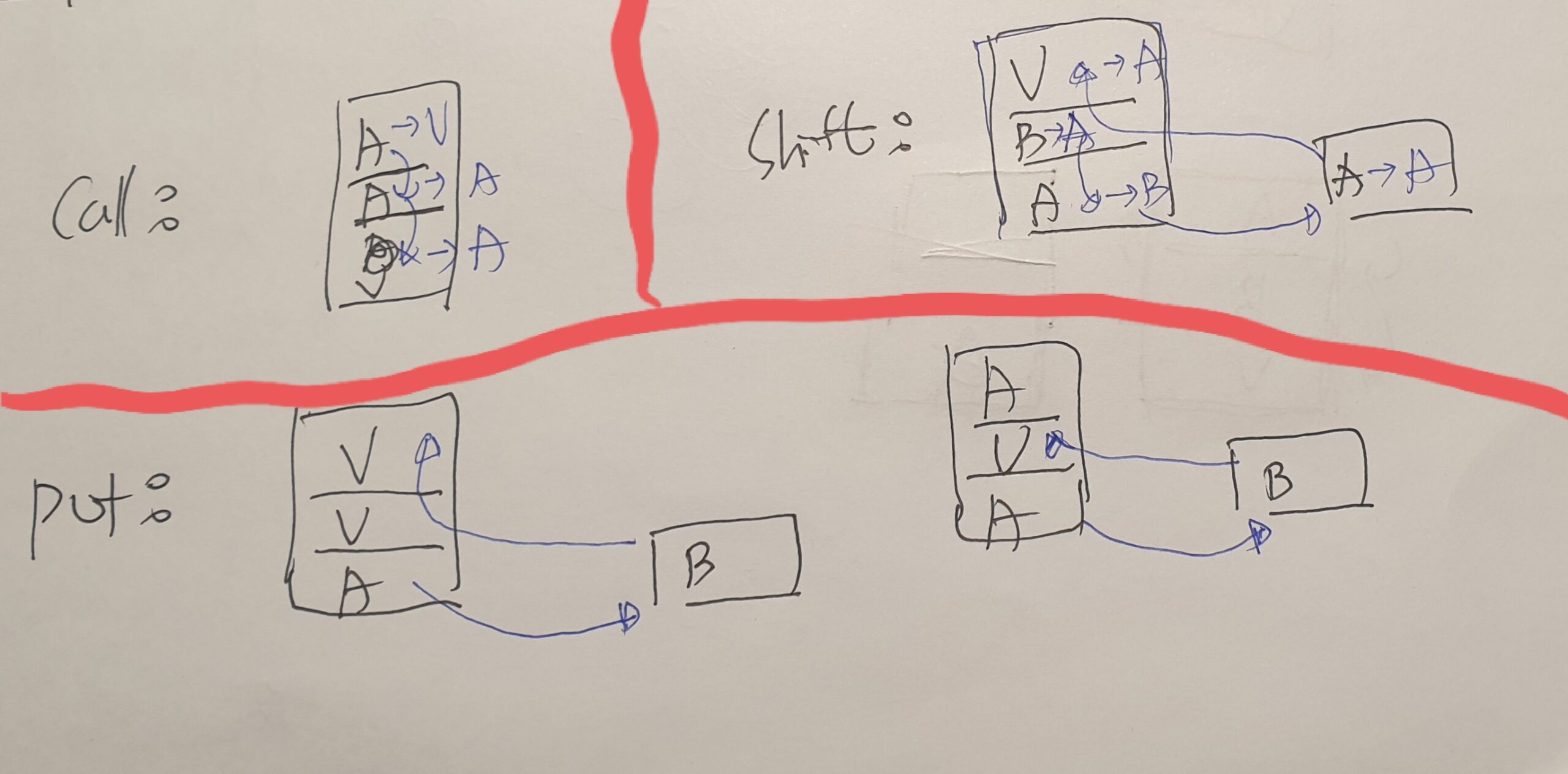
- get(call)은 그대로 유지. 2열 대차를 6번 셀로 call하고, 1열 대차를 2열로 이동. 2열 대차는 공대차로 채워줌.
- put은 1열이 비어 있으면 2열로 왔다 1열로 이동하도록 수정.
- put은 기존에 6번 셀까지 끌어 당겼으나(6번이 A, 7번이 B 표시부, put 동작시 6번은 A->V, 7번은 B->A로 변경되었음), 문제를 쉽게 풀기 위해서 7번 셀만 수정(put 실행시 7번만 B->V로 수정, 7번에 있던 B 대차는 화살표 표시까지 깊게 들어감).
- shiftX1, X2, X3 조건 추가.(전체 행동은 기존 get 3개, put 3개, shift X1/X2/X3 3개, getX3Y3 1개 총 10개로 증가)
성공하면 총 점 0점 이상을 획득한다. 100회 샘플 성공, 실패를 세어보면 아래와 같다.
episode: 0 score: 220 episode: 1 score: -100 episode: 2 score: 220 episode: 3 score: 200 episode: 4 score: 200 episode: 5 score: 220 episode: 6 score: 190 episode: 7 score: -100 episode: 8 score: 170 episode: 9 score: 200 episode: 10 score: 200 episode: 11 score: -100 episode: 12 score: 170 episode: 13 score: 200 episode: 14 score: 170 episode: 15 score: 190 episode: 16 score: 200 episode: 17 score: 190 episode: 18 score: 200 episode: 19 score: 200 episode: 20 score: 170 episode: 21 score: 160 episode: 22 score: 200 episode: 23 score: 170 episode: 24 score: 200 episode: 25 score: 200 episode: 26 score: 200 episode: 27 score: 200 episode: 28 score: 200 episode: 29 score: -100 episode: 30 score: 200 episode: 31 score: 170 episode: 32 score: 190 episode: 33 score: 190 episode: 34 score: 200 episode: 35 score: 190 episode: 36 score: 200 episode: 37 score: 200 episode: 38 score: 200 episode: 39 score: 200 episode: 40 score: 170 episode: 41 score: 170 episode: 42 score: 140 episode: 43 score: 170 episode: 44 score: 160 episode: 45 score: 220 episode: 46 score: 200 episode: 47 score: 200 episode: 48 score: -100 episode: 49 score: 200 episode: 50 score: 200 episode: 51 score: 170 episode: 52 score: 170 episode: 53 score: 170 episode: 54 score: -100 episode: 55 score: 200 episode: 56 score: 200 episode: 57 score: -100 episode: 58 score: 170 episode: 59 score: 200 episode: 60 score: 200 episode: 61 score: 190 episode: 62 score: 200 episode: 63 score: 200 episode: 64 score: 200 episode: 65 score: 200 episode: 66 score: 200 episode: 67 score: 190 episode: 68 score: 200 episode: 69 score: 200 episode: 70 score: 200 episode: 71 score: 200 episode: 72 score: 170 episode: 73 score: 190 episode: 74 score: 170 episode: 75 score: 200 episode: 76 score: 200 episode: 77 score: 190 episode: 78 score: 200 episode: 79 score: 220 episode: 80 score: 200 episode: 81 score: 200 episode: 82 score: 170 episode: 83 score: 200 episode: 84 score: 200 episode: 85 score: -100 episode: 86 score: 200 episode: 87 score: 200 episode: 88 score: 200 episode: 89 score: 200 episode: 90 score: -100 episode: 91 score: 170 episode: 92 score: 170 episode: 93 score: 170 episode: 94 score: -100 episode: 95 score: 200 episode: 96 score: 200 episode: 97 score: 170 episode: 98 score: 190 episode: 99 score: 170
총 100회 중 10번 실패 했는데, 각 경우를 보면.
episode: 1 score: -100 episode: 7 score: -100 episode: 11 score: -100 episode: 29 score: -100 episode: 48 score: -100 episode: 54 score: -100 episode: 57 score: -100 episode: 85 score: -100 episode: 90 score: -100 episode: 94 score: -100
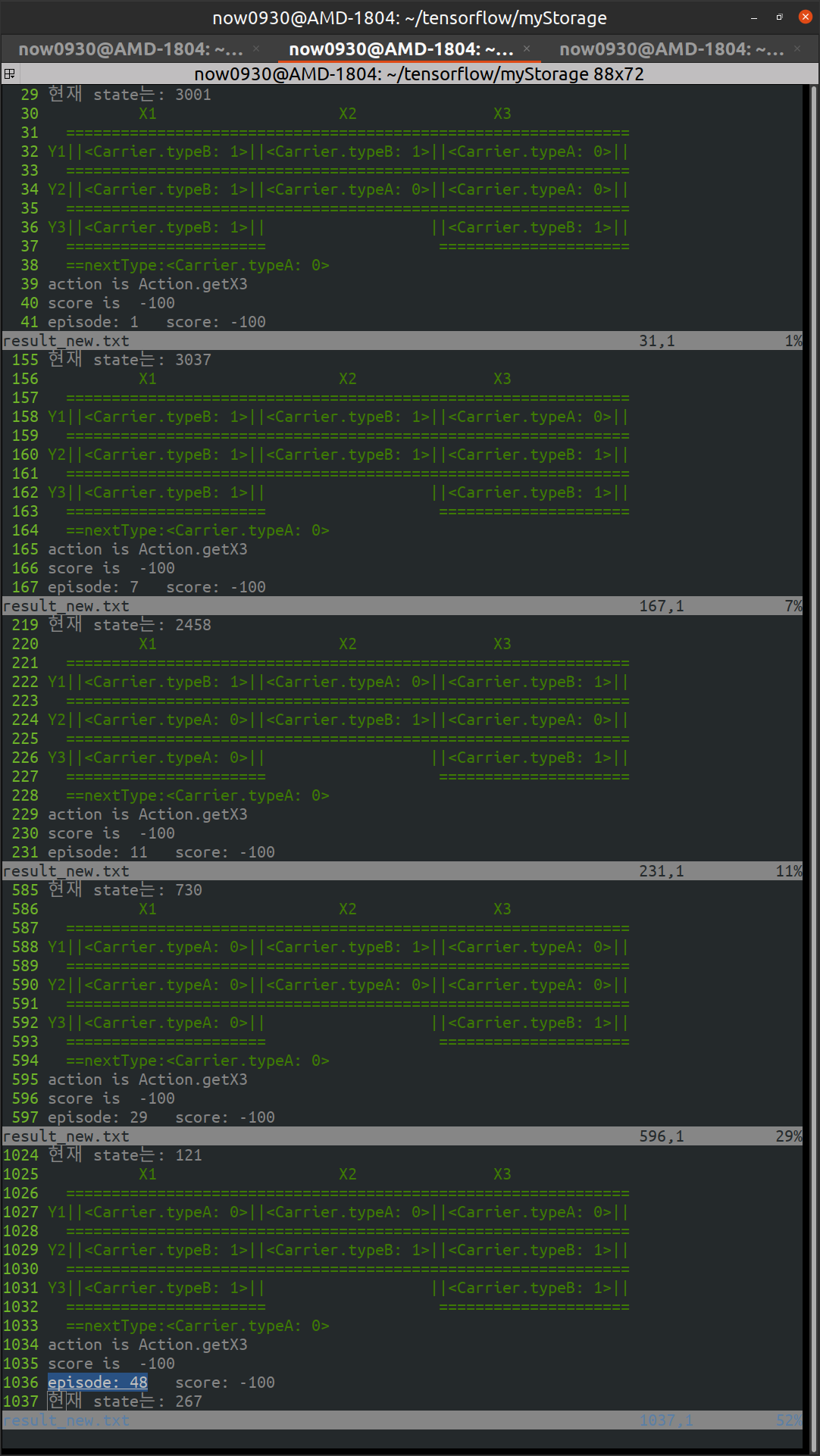
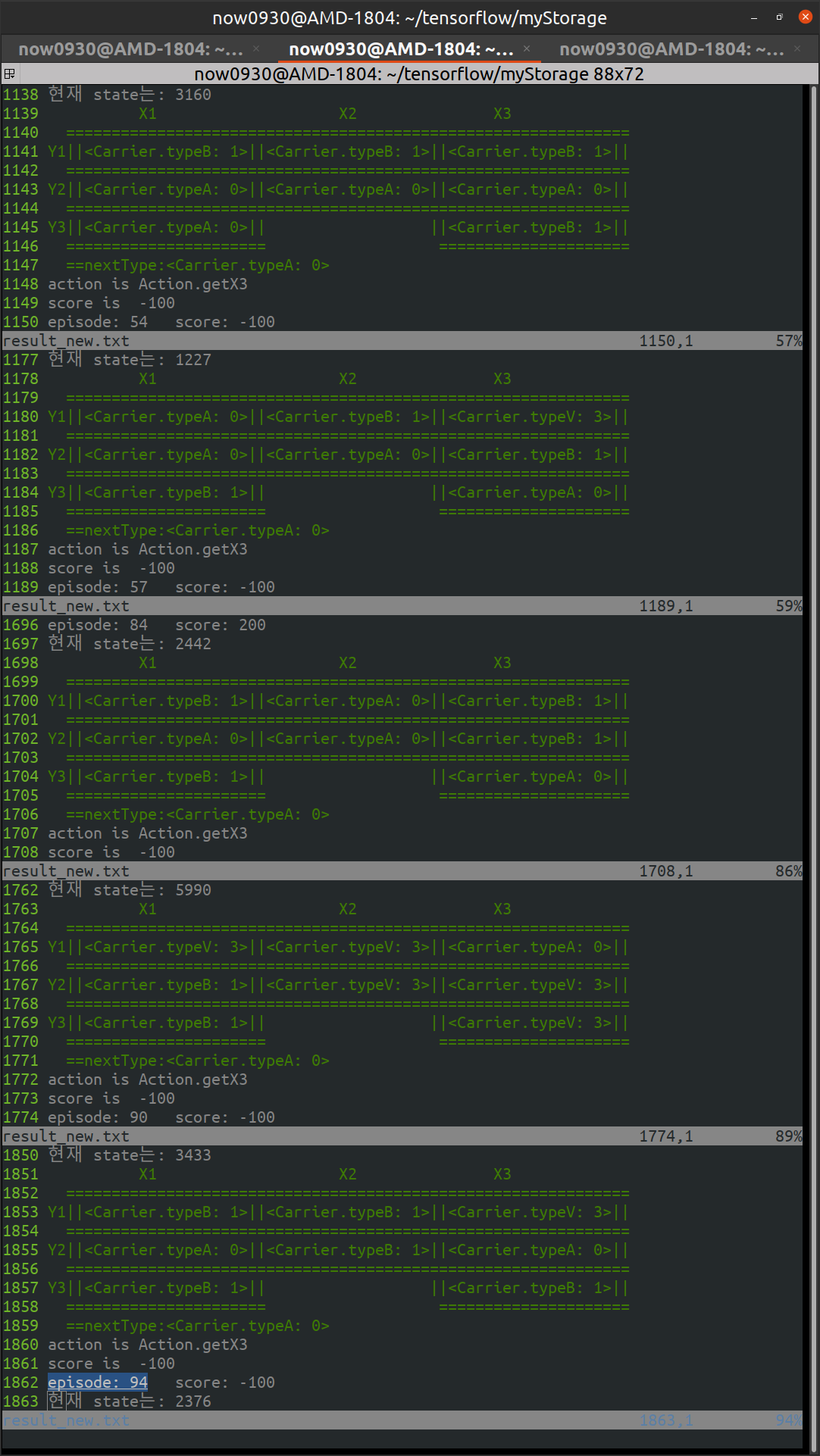
초기화 했을 경우 적어도 대차가 이동할 한 개 공간이 있도록 환경을 설정했는데, 왜인지 잘 안되었다. 이 에피소드는 절대 성공할 수 없다. 에피소드 57, 90, 94는 빈 공간이 있는데도 삽질했다. 이 부분을 어떻게 학습시켜야 할지 모르겠다.
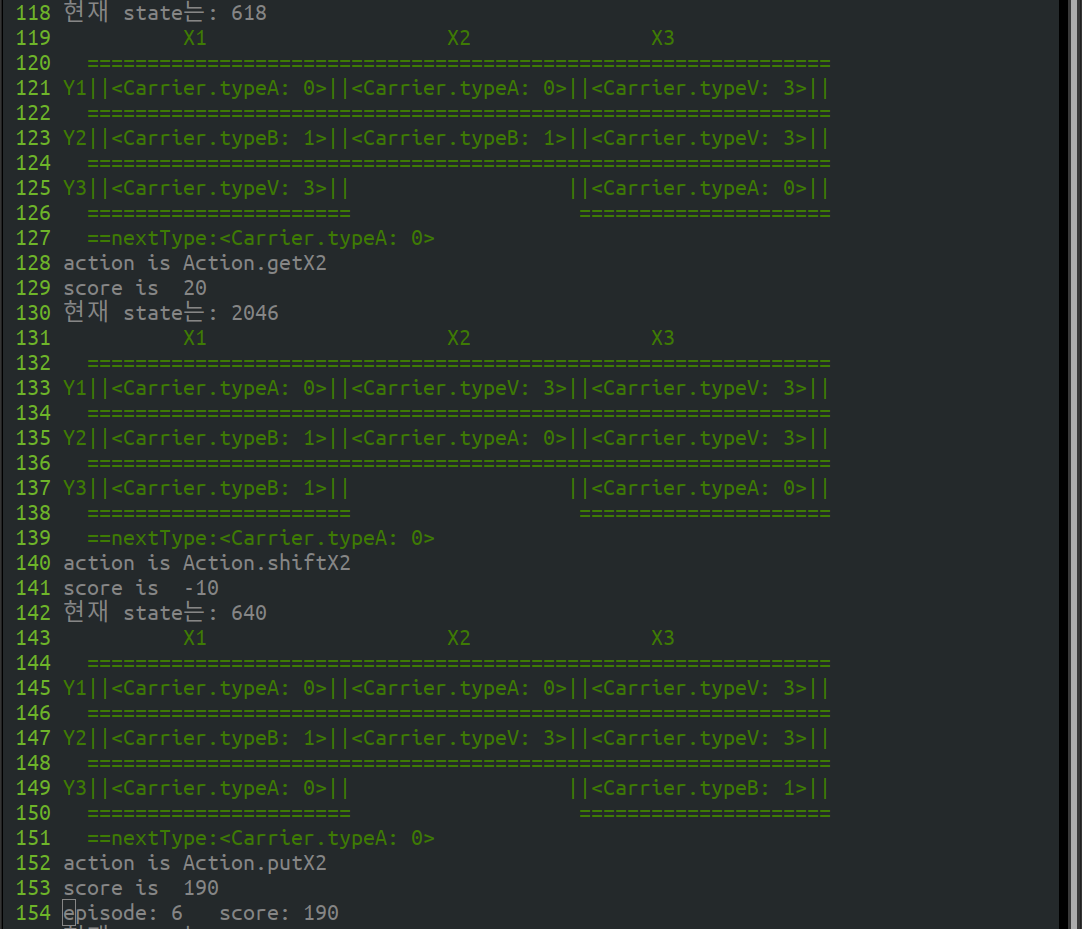
성공한 경우를 보면 에피소드 6은 A 대차가 뒤쪽에 숨겨져 있지만, call, shift 로 순환시켰다. 마지막에 put으로 X2, Y1 위치로 A 대차를 집어 넣었다.
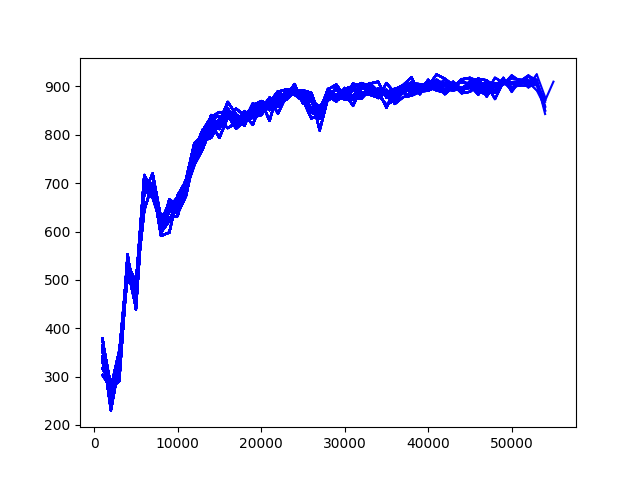
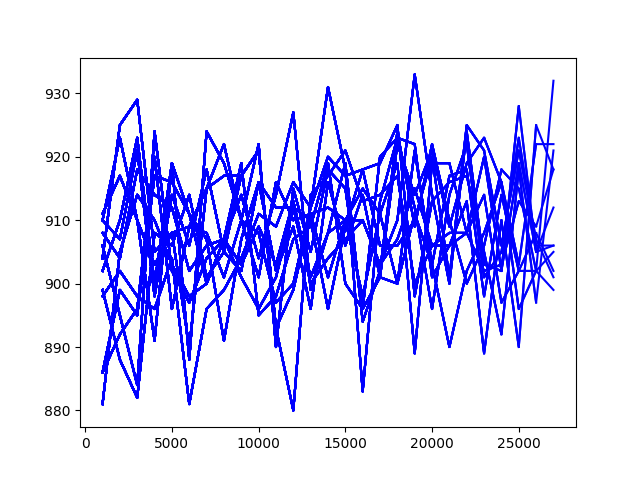
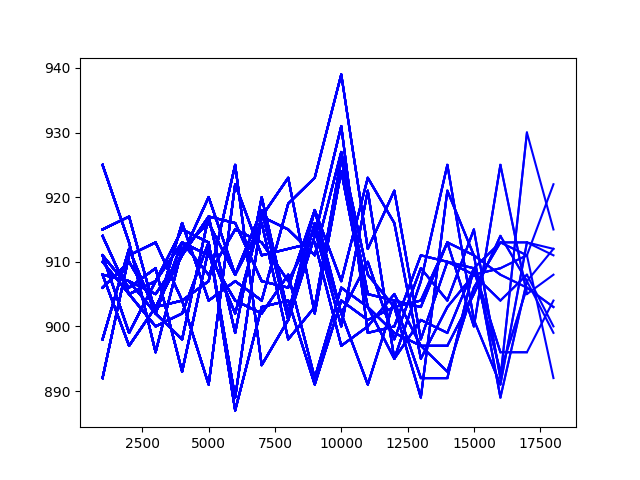
총 10시간, 10만회 * 12 thread 학습 시켰다. 뒤쪽으로 갈 수록 학습 효율이 떨어지는데, 마지막 학습에서 의미없이 연속으로 공대차 call 행동을 안하게 된 듯 하다. GTX 1060 6GB도 나름 쓸만하다.
여기에서 마무리 해야겠다.